Elasticsearch-databas
Elasticsearch är en av de mest populära NoSQL-databaserna som används för att lagra och söka efter textbaserad data. Den är baserad på Lucene-indexeringstekniken och möjliggör sökning i millisekunder baserat på data som är indexerade.
Baserat på Elasticsearch-webbplatsen är här definitionen:
Elasticsearch är en öppen källkodsdistribuerad, RESTful sök- och analysmotor som kan lösa ett växande antal användningsfall.
Det var några ord på hög nivå om Elasticsearch. Låt oss förstå begreppen i detalj här.
- Distribuerad: Elasticsearch delar upp data som den innehåller i flera noder och användningsområden mästare-slav algoritm internt
- Rogivande: Elasticsearch stöder databasfrågor via REST API: er. Det betyder att vi kan använda enkla HTTP-samtal och använda HTTP-metoder som GET, POST, PUT, DELETE etc. för att komma åt data.
- Sök- och analysmotor: ES stöder mycket analytiska frågor för att köras i systemet som kan bestå av aggregerade frågor och flera typer, som strukturerade, ostrukturerade och geofrågor.
- Horisontellt skalbar: Denna typ av skräpning avser att lägga till fler maskiner i ett befintligt kluster. Detta innebär att ES kan acceptera fler noder i sitt kluster och tillhandahålla ingen stillestånd för nödvändiga uppgraderingar till systemet. Titta på bilden nedan för att förstå skalningskoncepten:
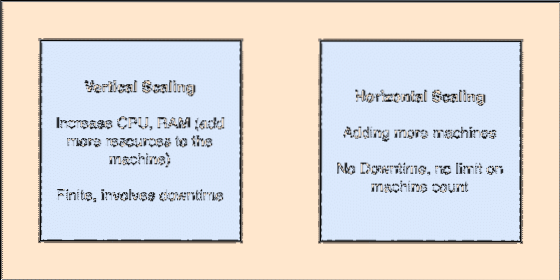
Vertikal och horisontell svindling
Komma igång med Elasticsearch Database
För att kunna börja använda Elasticsearch måste den installeras på maskinen. För att göra detta, läs Installera ElasticSearch på Ubuntu.
Se till att du har en aktiv ElasticSearch-installation om du vill prova exempel som vi presenterar senare i lektionen.
Elasticsearch: Concepts & Components
I det här avsnittet kommer vi att se vilka komponenter och begrepp som ligger i hjärtat av Elasticsearch. Att förstå om dessa begrepp är viktigt för att förstå hur ES fungerar:
- Klunga: Ett kluster är en samling servermaskiner (noder) som innehåller data. Data delas mellan flera noder så att de kan replikeras och SPoF (Single Point of Failure) inträffar inte med ES-servern. Standardnamnet på klustret är elasticsearch. Varje nod i ett kluster ansluter till klustret med en URL och klusternamnet så det är viktigt att hålla detta namn distinkt och tydligt.
- Nod: En nodmaskin är en del av en server och kallas en enda maskin. Den lagrar data och tillhandahåller indexering och sökfunktioner, tillsammans med andra noder till klustret.
På grund av begreppet horisontell skalning kan vi praktiskt taget lägga till ett oändligt antal noder i ett ES-kluster för att ge det mycket mer styrka och indexeringsfunktioner.
- Index: Ett index är en samling dokument med något liknande egenskaper. Ett index liknar ungefär en databas i en SQL-baserad miljö.
- Typ: En typ används för att separera data mellan samma index. Kunddatabasen / indexet kan till exempel ha flera typer, som användare, betalningstyp osv.
Observera att typer avskrivs från ES v6.0.0 och framåt. Läs här varför detta gjordes.
- Dokumentera: Ett dokument är den lägsta nivån på enheten som representerar data. Föreställ dig det som ett JSON-objekt som innehåller dina data. Det är möjligt att indexera så många dokument i ett index.
Typer av sökning i Elasticsearch
Elasticsearch är känt för sina nästan realtidssökningsmöjligheter och de flexibiliteter som det ger med den typ av data som indexeras och söks. Låt oss börja studera hur man använder sökning med olika typer av data.
- Structured Search: Denna typ av sökning körs på data som har ett fördefinierat format som datum, tider och siffror. Med ett fördefinierat format kommer flexibiliteten att köra vanliga operationer som att jämföra värden i ett intervall av datum. Intressant, textdata kan också struktureras. Detta kan hända när ett fält har ett fast antal värden. Till exempel kan databasens namn vara MySQL, MongoDB, Elasticsearch, Neo4J etc. Med strukturerad sökning är svaret på frågorna vi kör antingen ja eller nej.
- Fulltextsökning: Denna typ av sökning är beroende av två viktiga faktorer, Relevans och Analys. Med relevans bestämmer vi hur väl vissa data matchar frågan genom att definiera en poäng till de resulterande dokumenten. Denna poäng tillhandahålls av ES själv. Analys refererar till att bryta texten i normaliserade tokens för att skapa ett inverterat index.
- Multifield-sökning: Eftersom antalet analytiska frågor som någonsin ökar för de lagrade data i ES, möter vi vanligtvis inte bara enkla matchningsfrågor. Kraven har ökat för att köra frågor som sträcker sig över flera fält och har en sorterad lista med data som returneras till oss av själva databasen. På det här sättet kan data vara närvarande för slutanvändaren på ett mycket mer effektivt sätt.
- Närhetsmatchning: Frågor i dag är mycket mer än bara att identifiera om vissa textdata innehåller en annan sträng eller inte. Det handlar om att fastställa förhållandet mellan data så att det kan poängsättas och matchas till det sammanhang där data matchas. Till exempel:
- Boll träffade John
- John slog bollen
- John köpte en ny boll som träffades i Jaen-trädgården
En matchningsfråga hittar alla tre dokument när de söks Bollslag. En närhetssökning kan berätta hur långt dessa två ord visas i samma rad eller stycke på grund av vilka de matchade.
- Partiell matchning: Det är ofta vi behöver köra partiella matchningsfrågor. Partiell matchning tillåter oss att köra frågor som matchar delvis. För att visualisera detta, låt oss titta på en liknande SQL-baserad fråga:
SQL-frågor: partiell matchning
VAR namn som "% john%"
OCH namn LIKE "% red%"
OCH namn LIKE "% garden%"Vid vissa tillfällen behöver vi bara köra partiella matchningsfrågor även när de kan betraktas som brute-force-tekniker.
Integration med Kibana
När det gäller en analysmotor behöver vi vanligtvis köra analysfrågor i en Business-Intelligence (BI) -domän. När det gäller affärsanalytiker eller dataanalytiker skulle det inte vara rättvist att anta att människor kan ett programmeringsspråk när de vill visualisera data som finns i ES Cluster. Detta problem löses av Kibana. Kibana erbjuder så många fördelar för BI att människor faktiskt kan visualisera data med en utmärkt, anpassningsbar instrumentpanel och se data på ett ointressant sätt. Låt oss titta på några av fördelarna här.
Interaktiva diagram
Kärnan i Kibana är interaktiva diagram som dessa: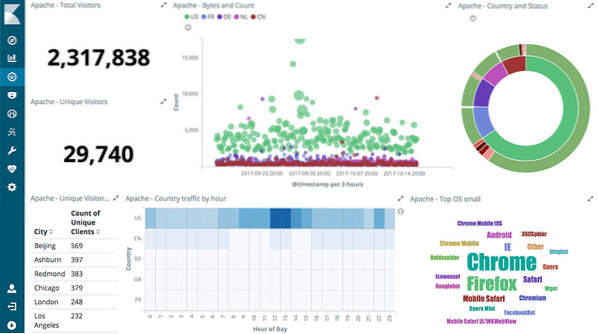
Kibana levereras med olika typer av diagram som cirkeldiagram, sunbursts, histogram och mycket mer som använder ES: s kompletta aggregeringsfunktioner.
Kartläggningsstöd
Kibana stöder också fullständig Geo-aggregering som gör att vi kan geokarta våra data. Är det inte så coolt?!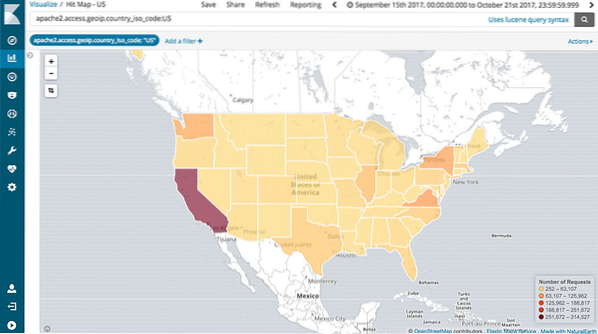
Förbyggda aggregat och filter
Med förbyggda aggregat och filter är det möjligt att bokstavligen frag, släppa och köra mycket optimerade frågor inom Kibana Dashboard. Med bara några få klick är det möjligt att köra aggregerade frågor och presentera resultat i form av interaktiva diagram.
Enkel distribution av instrumentpaneler
Med Kibana är det också väldigt enkelt att dela instrumentpaneler till en mycket bredare publik utan att göra några ändringar på instrumentpanelen med hjälp av Endast Dashboard-läge. Vi kan enkelt infoga instrumentpaneler i vår interna wiki eller webbsidor.
Funktionsbilder tagna från Kibana produktsida.
Använda Elasticsearch
Kör följande kommando för att se instansinformation och klusterinformation: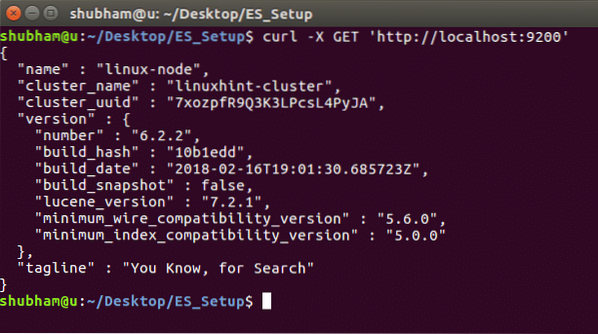
Nu kan vi försöka infoga lite data i ES med följande kommando:
Infoga data
krulla \-X POST 'http: // localhost: 9200 / linuxhint / hej / 1' \
-H 'Innehållstyp: applikation / json' \
-d '"name": "LinuxHint"' \
Här är vad vi får tillbaka med det här kommandot:
Låt oss försöka få data nu:
Få data
curl -X GET 'http: // localhost: 9200 / linuxhint / hej / 1'När vi kör det här kommandot får vi följande utdata:
Slutsats
I den här lektionen tittade vi på hur vi kan börja använda ElasticSearch som är en utmärkt Analytics Engine och ger utmärkt stöd för nästan realtidssökning i fri tid också.


