Innan du använder pandas pivottabell, se till att du förstår dina data och frågor du försöker lösa genom pivottabellen. Genom att använda denna metod kan du skapa kraftfulla resultat. Vi kommer att utarbeta i den här artikeln hur man skapar en pivottabell i pandas python.
Läs data från Excel-filen
Vi har laddat ner en Excel-databas över livsmedelsförsäljning. Innan du börjar implementera måste du installera några nödvändiga paket för att läsa och skriva excel-databasfiler. Skriv följande kommando i terminalavsnittet i din pycharm-editor:
pip installera xlwt openpyxl xlsxwriter xlrd
Läs nu data från Excel-bladet. Importera de obligatoriska pandabiblioteken och ändra sökvägen till din databas. Genom att köra följande kod kan data hämtas från filen.
importera pandor som pdimportera numpy som np
dtfrm = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
skriva ut (dtfrm)
Här läses informationen från excel-databasen för livsmedelsförsäljning och skickas till dataframe-variabeln.
Skapa pivottabell med Pandas Python
Nedan har vi skapat en enkel pivottabell med hjälp av livsmedelsförsäljningsdatabasen. Två parametrar krävs för att skapa en pivottabell. Den första är data som vi har överfört till dataramen, och den andra är ett index.
Pivotdata på ett index
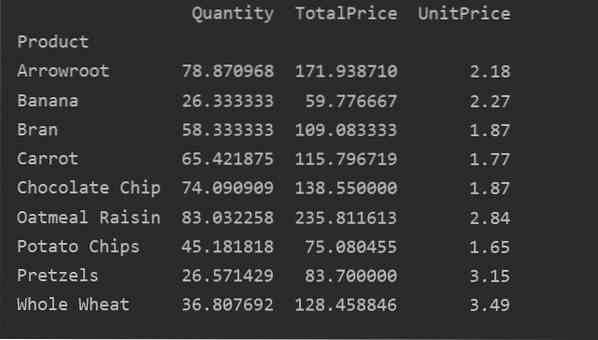
Indexet är funktionen i en pivottabell som låter dig gruppera dina data baserat på krav. Här har vi tagit 'Produkt' som index för att skapa en grundläggande pivottabell.
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataframe, index = ["Produkt"])
skriv ut (pivot_tble)
Följande resultat visas efter att källkoden ovan har körts:
Definiera kolumner uttryckligen
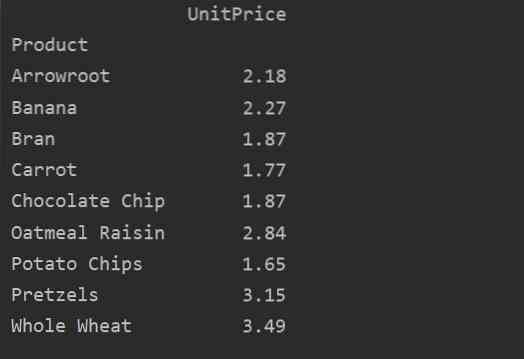
För mer analys av dina data, definiera kolumnnamnen uttryckligen med indexet. Till exempel vill vi visa den enda UnitPrice för varje produkt i resultatet. För detta ändamål, lägg till parametern värden i din pivottabell. Följande kod ger dig samma resultat:
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = 'Product', values = 'UnitPrice')
skriv ut (pivot_tble)
Pivotdata med flera index
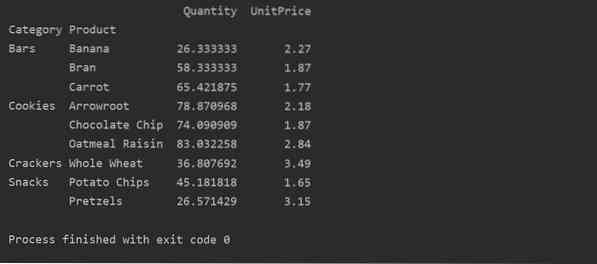
Data kan grupperas baserat på mer än en funktion som ett index. Genom att använda multiindexmetoden kan du få mer specifika resultat för dataanalys. Till exempel kommer produkter under olika kategorier. Så du kan visa indexet 'Produkt' och 'Kategori' med tillgängliga 'Antal' och 'Enhetspris' för varje produkt enligt följande:
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivottabell (dataframe, index = ["Category", "Product"], values = ["UnitPrice", "Quantity"])
skriv ut (pivot_tble)
Tillämpa aggregeringsfunktion i pivottabellen
I en pivottabell kan aggfunc användas för olika funktionsvärden. Den resulterande tabellen är en sammanfattning av funktionsdata. Den aggregerade funktionen gäller gruppdata i pivottabell. Som standard är aggregerad funktion np.betyda(). Men baserat på användarkraven kan olika aggregerade funktioner gälla för olika datafunktioner.
Exempel:
Vi har tillämpat aggregerade funktioner i detta exempel. Np.funktionen sum () används för funktionen 'Kvantitet' och np.medelvärdesfunktion () för funktionen 'UnitPrice'.
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
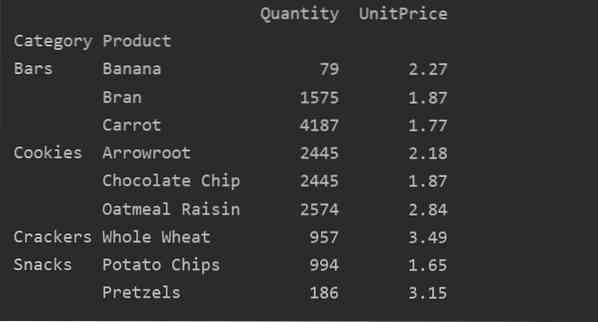
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], aggfunc = 'Quantity': np.summa, 'UnitPrice': np.betyda)
skriv ut (pivot_tble)
Efter att aggregeringsfunktionen har tillämpats för olika funktioner får du följande utdata:
Med hjälp av värdeparametern kan du också tillämpa aggregerad funktion för en viss funktion. Om du inte kommer att ange funktionens värde, samlar den databasens numeriska funktioner. Genom att följa den angivna källkoden kan du använda den samlade funktionen för en specifik funktion:
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
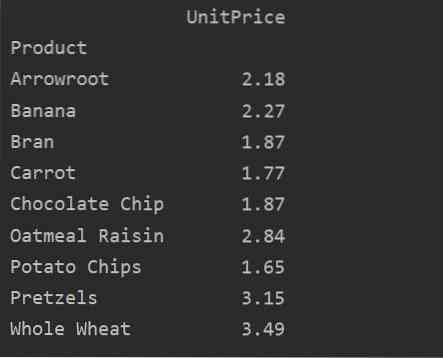
pivot_tble = pd.pivottabell (dataframe, index = ['Product'], värden = ['UnitPrice'], aggfunc = np.betyda)
skriv ut (pivot_tble)
Olika mellan värden vs. Kolumner i pivottabellen
Värdena och kolumnerna är den viktigaste förvirrande punkten i pivottabellen. Det är viktigt att notera att kolumner är valfria fält som visar den resulterande tabellens värden horisontellt överst. Aggregeringsfunktionen aggfunc gäller det värderingsfält som du listar.
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
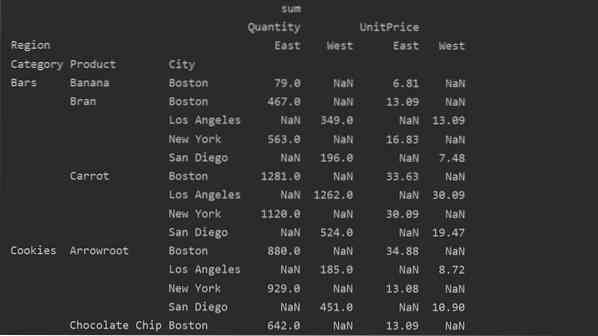
pivot_tble = pd.pivot_table (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
kolumner = ['Region'], aggfunc = [np.belopp])
skriv ut (pivot_tble)
Hantering av saknade data i pivottabellen
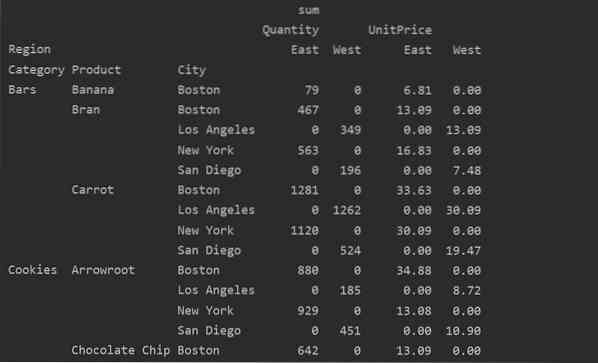
Du kan också hantera de värden som saknas i pivottabellen genom att använda 'fill_value' Parameter. Detta låter dig ersätta NaN-värdena med något nytt värde som du anger för att fylla.
Till exempel tog vi bort alla nollvärden från ovanstående resultattabell genom att köra följande kod och ersätter NaN-värdena med 0 i hela den resulterande tabellen.
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
kolumner = ['Region'], aggfunc = [np.summa], fill_value = 0)
skriv ut (pivot_tble)
Filtrering i pivottabell
När resultatet har genererats kan du använda filtret med standarddataframfunktionen. Låt oss ta ett exempel. Filtrera de produkter vars UnitPrice är mindre än 60. Den visar de produkter vars pris är lägre än 60.
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabell (dataframe, index = 'Produkt', värden = 'UnitPrice', aggfunc = 'summa')
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
skriva ut (lågt pris)

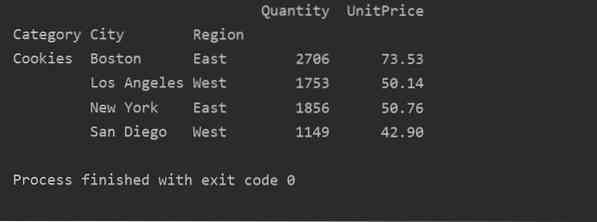
Genom att använda en annan frågemetod kan du filtrera resultat. Till exempel har vi till exempel filtrerat kakakategorin baserat på följande funktioner:
importera pandor som pdimportera numpy som np
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivottabell (dataframe, index = ["Category", "City", "Region"], values = ["UnitPrice", "Quantity"], aggfunc = np.belopp)
pt = pivot_tble.fråga ('Category == ["Cookies"]')
skriva ut (pt)
Produktion:
Visualisera data för pivottabellen
Följ följande metod för att visualisera pivottabelldata:
importera pandor som pdimportera numpy som np
importera matplotlib.pyplot som plt
dataframe = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], values = ["UnitPrice"])
pivot_tble.plot (kind = 'bar');
plt.show()
I ovanstående visualisering har vi visat enhetspriset för de olika produkterna tillsammans med kategorier.

Slutsats
Vi undersökte hur du kan skapa en pivottabell från dataramen med Pandas python. En pivottabell låter dig generera djupgående insikter i dina datamängder. Vi har sett hur man genererar en enkel pivottabell med flera index och tillämpar filtren på pivottabeller. Dessutom har vi också visat att plotta pivottabeldata och fylla saknade data.

