- 1 för sant eller
- 0 för falskt
Den viktigaste betydelsen av logistisk regression:
- De oberoende variablerna får inte vara multikollinearitet; om det finns något förhållande, bör det vara väldigt lite.
- Datauppsättningen för logistisk regression bör vara tillräckligt stor för att få bättre resultat.
- Endast dessa attribut ska finnas där i datasetet, vilket har någon betydelse.
- De oberoende variablerna måste vara i enlighet med loggodds.
Att bygga modellen för logistisk återgång, vi använder scikit-lär dig bibliotek. Processen för den logistiska regressionen i python ges nedan:
- Importera alla nödvändiga paket för logistisk regression och andra bibliotek.
- Ladda upp datasetet.
- Förstå de oberoende datasetvariablerna och de beroende variablerna.
- Dela datauppsättningen i tränings- och testdata.
- Initiera den logistiska regressionsmodellen.
- Anpassa modellen med träningsdataset.
- Förutsäg modellen med testdata och beräkna modellens noggrannhet.
Problem: De första stegen är att samla in datauppsättningen som vi vill använda Logistisk återgång. Datauppsättningen som vi ska använda här är för MS-antagningsdataset. Denna dataset har fyra variabler och varav tre är oberoende variabler (GRE, GPA, work_experience), och en är en beroende variabel (godkänd). Denna dataset kommer att berätta om kandidaten kommer att få antagning eller inte till ett prestigefyllt universitet baserat på deras GPA, GRE eller work_experience.
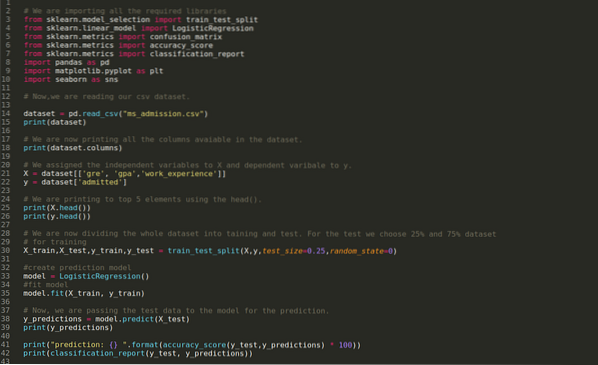
Steg 1: Vi importerar alla nödvändiga bibliotek som vi behöver för python-programmet.
Steg 2: Nu laddar vi vår ms-inlämningsdataset med read_csv-pandafunktionen.

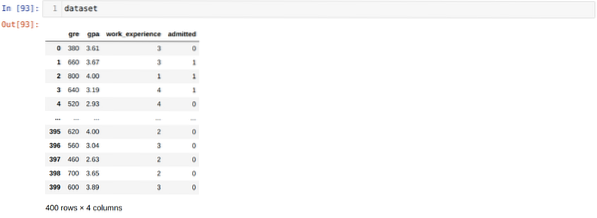
Steg 3: Datauppsättningen ser ut nedan:
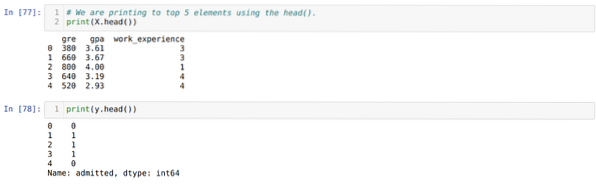
Steg 4: Vi kontrollerar alla tillgängliga kolumner i datasetet och ställer sedan in alla oberoende variabler till variabel X och beroende variabler till y, som visas i nedanstående skärmdump.

Steg 5: Efter att ha satt de oberoende variablerna till X och den beroende variabeln till y, skriver vi nu ut här för att korskontrollera X och y med hjälp av huvudpandafunktionen.
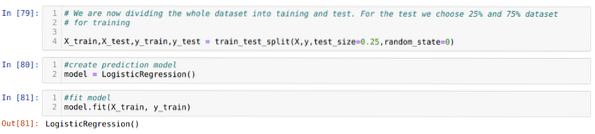
Steg 6: Nu ska vi dela upp hela datasetet i utbildning och test. För detta använder vi metoden train_test_split för sklearn. Vi har gett 25% av hela datasetet till testet och de återstående 75% av datasetet till träningen.
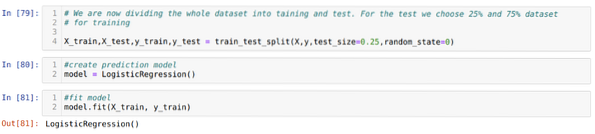
Steg 7: Nu ska vi dela upp hela datasetet i utbildning och test. För detta använder vi metoden train_test_split för sklearn. Vi har gett 25% av hela datasetet till testet och de återstående 75% av datasetet till träningen.
Sedan skapar vi Logistic Regression-modellen och passar träningsdata.
Steg 8: Nu är vår modell redo för förutsägelse, så vi skickar nu testdata (X_test) till modellen och fick resultaten. Resultaten visar (y_prognoser) att värdena 1 (tillåtna) och 0 (ej tillåtna).

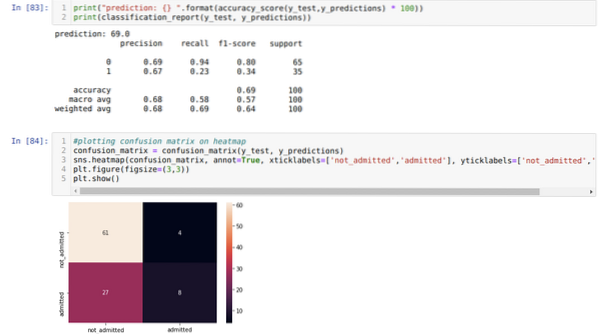
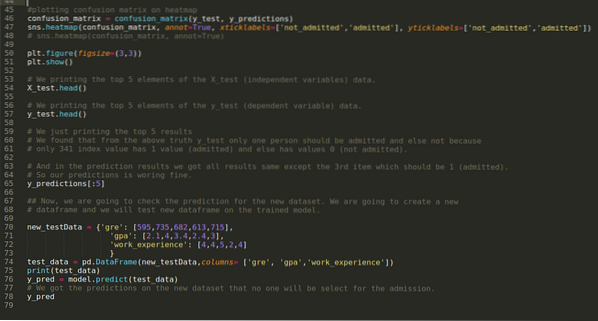
Steg 9: Nu skriver vi ut klassificeringsrapporten och förvirringsmatrisen.
Klassificeringsrapporten visar att modellen kan förutsäga resultaten med en noggrannhet på 69%.
Förvirringsmatrisen visar de totala uppgifterna om X_test som:
TP = sanna positiva = 8
TN = sanna negativ = 61
FP = Falska positiva = 4
FN = falska negativ = 27
Så den totala noggrannheten enligt confusion_matrix är:
Noggrannhet = (TP + TN) / Total = (8 + 61) / 100 = 0.69
Steg 10: Nu kommer vi att korskontrollera resultatet genom utskrift. Så vi skriver bara ut de fem bästa elementen i X_test och y_test (faktiskt sant värde) med hjälp av huvudpandafunktionen. Sedan skriver vi också ut de fem bästa resultaten av förutsägelserna som visas nedan:
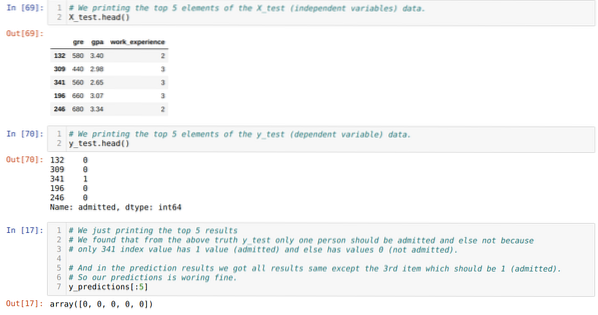
Vi kombinerar alla tre resultaten i ett ark för att förstå förutsägelserna som visas nedan. Vi kan se att förutom 341 X_test-data, som var sant (1), är förutsägelsen falsk (0) annat. Så våra modellprognoser fungerar 69%, som vi redan har visat ovan.

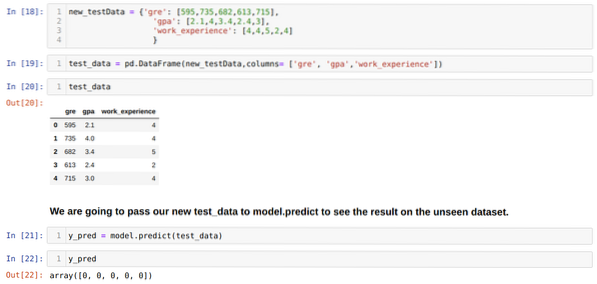
Steg 11: Så vi förstår hur modellförutsägelser görs på den osedda datasetet som X_test. Så vi skapade bara ett slumpmässigt nytt dataset med en pandas dataframe, skickade den till den utbildade modellen och fick resultatet nedan.
Den fullständiga koden i python nedan:
Koden för den här bloggen, tillsammans med datasetet, finns på följande länk
https: // github.com / shekharpandey89 / logistisk-regression


