- Vad är Python Seaborn?
- Typer av tomter som vi kan konstruera med Seaborn
- Arbeta med flera tomter
- Några alternativ för Python Seaborn
Det här ser ut som mycket att täcka. Låt oss komma igång nu.
Vad är Python Seaborn-biblioteket?
Seaborn-biblioteket är ett Python-paket som låter oss göra infografik baserad på statistiska data. Eftersom den är gjord ovanpå matplotlib så är den till sin natur kompatibel med den. Dessutom stöder den NumPy och Pandas datastruktur så att plottning kan göras direkt från dessa samlingar.
Att visualisera komplexa data är en av de viktigaste Seaborn tar hand om. Om vi skulle jämföra Matplotlib med Seaborn kan Seaborn göra de sakerna enkla som är svåra att uppnå med Matplotlib. Det är dock viktigt att notera det Seaborn är inte ett alternativ till Matplotlib utan ett komplement till det. Under hela denna lektion kommer vi också att använda Matplotlib-funktioner i kodavsnitten. Du väljer att arbeta med Seaborn i följande användningsfall:
- Du har statistiska tidsseriedata som ska plottas med en osäkerhet kring uppskattningarna
- Att visuellt fastställa skillnaden mellan två delmängder av data
- Att visualisera de univariata och bivariata distributionerna
- Lägga till mycket mer visuell tillgivenhet till matplotlib-tomterna med många inbyggda teman
- Att passa och visualisera maskininlärningsmodeller genom linjär regression med oberoende och beroende variabler
Bara en anmärkning innan vi börjar är att vi använder en virtuell miljö för den här lektionen som vi gjorde med följande kommando:
python -m virtualenv seabornkälla seaborn / bin / aktivera
När den virtuella miljön är aktiv kan vi installera Seaborn-biblioteket i det virtuella env så att exempel vi skapar nästa kan köras:
pip installera seabornDu kan också använda Anaconda för att köra dessa exempel, vilket är lättare. Om du vill installera den på din maskin, titta på lektionen som beskriver ”Hur man installerar Anaconda Python på Ubuntu 18.04 LTS ”och dela din feedback. Låt oss nu gå vidare till olika typer av tomter som kan konstrueras med Python Seaborn.
Använda Pokémon Dataset
För att hålla den här lektionen praktisk använder vi Pokémon-dataset som kan laddas ner från Kaggle. För att importera denna dataset till vårt program använder vi Pandas-biblioteket. Här är all import vi utför i vårt program:
importera pandor som pdfrån matplotlib importera pyplot som plt
importera seaborn som sns
Nu kan vi importera datamängden till vårt program och visa några av exempeldata med Pandas som:
df = pd.read_csv ('Pokemon.csv ', index_col = 0)df.huvud()
Observera att för att köra kodavsnittet ovan ska CSV-datasetet finnas i samma katalog som själva programmet. När vi har kört ovanstående kodavsnitt ser vi följande utdata (i Anaconda Jupyters anteckningsbok):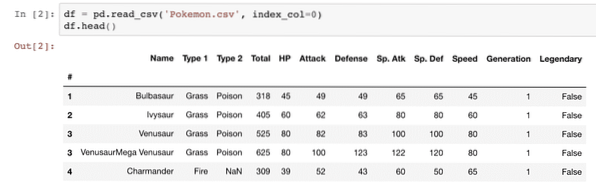
Plottning linjär regressionskurva
En av de bästa med Seaborn är de intelligenta plottningsfunktionerna som tillhandahålls, som inte bara visualiserar datauppsättningen vi tillhandahåller den utan också konstruerar regressionsmodeller runt den. Det är till exempel möjligt att konstruera ett linjärt regressionsdiagram med en enda kodrad. Så här gör du:
sns.lmplot (x = 'Attack', y = 'Defense', data = df)När vi har kört kodavsnittet ovan ser vi följande utdata: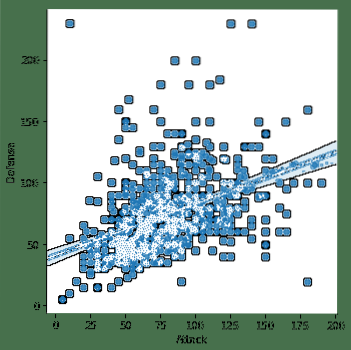
Vi märkte några viktiga saker i ovanstående kodavsnitt:
- Det finns dedikerad plottningsfunktion tillgänglig i Seaborn
- Vi använde Seaborns anpassnings- och plottningsfunktion som gav oss en linjär regressionslinje som den modellerade själv
Var inte rädd om du trodde att vi inte kunde ha en tomt utan den regressionslinjen. Vi kan ! Låt oss prova ett nytt kodavsnitt nu, liknande det sista:
sns.lmplot (x = 'Attack', y = 'Defense', data = df, fit_reg = False)Den här gången kommer vi inte att se regressionslinjen i vår plot: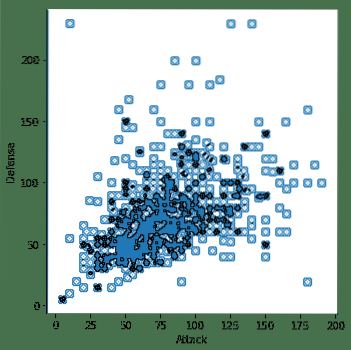
Nu är detta mycket tydligare (om vi inte behöver den linjära regressionslinjen). Men det här är inte bara över ännu. Seaborn tillåter oss att göra annorlunda denna plot och det är vad vi kommer att göra.
Konstruera rutor
En av de största funktionerna i Seaborn är hur den lätt accepterar Pandas Dataframes-struktur för att plotta data. Vi kan helt enkelt skicka en datafram till Seaborn-biblioteket så att den kan konstruera en boxplot ur den:
sns.boxplot (data = df)När vi har kört kodavsnittet ovan ser vi följande utdata:
Vi kan ta bort den första avläsningen av totalt eftersom det ser lite besvärligt ut när vi faktiskt planerar enskilda kolumner här:
# Ny boxplot med stats_df
sns.boxplot (data = stats_df)
När vi har kört kodavsnittet ovan ser vi följande utdata: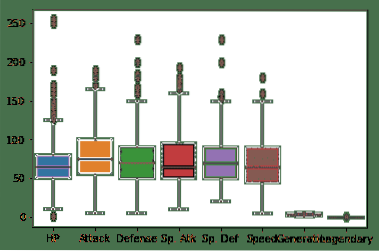
Swarm Plot med Seaborn
Vi kan konstruera en intuitiv designad svärmtomt med Seaborn. Vi kommer återigen att använda dataframen från Pandas som vi laddade tidigare men den här gången kommer vi att ringa Matplotlibs showfunktion för att visa plot vi gjorde. Här är kodavsnittet:
sns.set_context ("papper")sns.swarmplot (x = "Attack", y = "Defense", data = df)
plt.show()
När vi har kört kodavsnittet ovan ser vi följande utdata: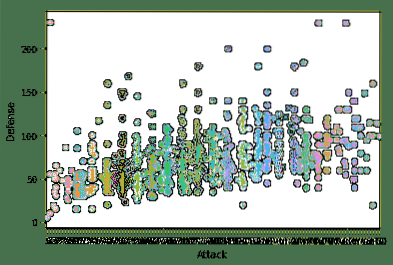
Genom att använda ett Seaborn-sammanhang tillåter vi Seaborn att lägga till en personlig touch och flytande design för handlingen. Det är möjligt att anpassa denna tomt ytterligare med anpassad teckenstorlek som används för etiketter i plottet för att göra läsningen enklare. För att göra detta skickar vi fler parametrar till set_context-funktionen som fungerar precis som vad de låter. För att till exempel ändra etikettens teckenstorlek använder vi teckensnitt.storleksparameter. Här är kodavsnittet för att göra ändringen:
sns.swarmplot (x = "Attack", y = "Defense", data = df)
plt.show()
När vi har kört kodavsnittet ovan ser vi följande utdata: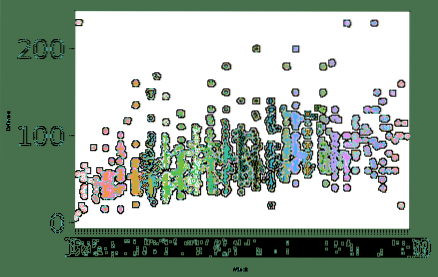
Teckensnittstorleken för etiketten ändrades baserat på de parametrar som vi angav och värdet för teckensnittet.storleksparameter. En sak Seaborn är expert på är att göra tomten väldigt intuitiv för praktisk användning och det betyder att Seaborn inte bara är ett praktiskt Python-paket utan faktiskt något vi kan använda i våra produktionsdistributioner.
Lägga till en titel i tomter
Det är enkelt att lägga till titlar i våra tomter. Vi behöver bara följa ett enkelt förfarande för att använda funktionerna på axelnivå där vi kommer att kalla set_title () fungerar som vi visar i kodavsnittet här:
sns.set_context ("paper", font_scale = 3, rc = "font.storlek ": 8," axlar.etikettstorlek ": 5)my_plot = sns.swarmplot (x = "Attack", y = "Defense", data = df)
min_plott.set_title ("LH Swarm Plot")
plt.show()
När vi har kört kodavsnittet ovan ser vi följande utdata: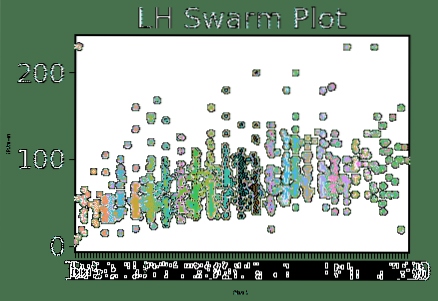
På så sätt kan vi lägga till mycket mer information till våra tomter.
Seaborn vs Matplotlib
När vi tittade på exemplen i den här lektionen kan vi identifiera att Matplotlib och Seaborn inte kan jämföras direkt men de kan ses som komplement till varandra. En av funktionerna som tar Seaborn 1 steg framåt är hur Seaborn kan visualisera data statistiskt.
För att få ut det mesta av Seaborn-parametrarna rekommenderar vi starkt att du tittar på Seaborn-dokumentationen och ta reda på vilka parametrar som ska användas för att göra din tomt så nära affärsbehov som möjligt.
Slutsats
I den här lektionen tittade vi på olika aspekter av detta datavisualiseringsbibliotek som vi kan använda med Python för att generera vackra och intuitiva grafer som kan visualisera data i en form som företaget vill ha från en plattform. Seaborm är ett av de viktigaste visualiseringsbiblioteken när det gäller datateknik och presentation av data i de flesta visuella former, definitivt en färdighet vi måste ha under vårt bälte eftersom det gör det möjligt för oss att bygga linjära regressionsmodeller.
Dela din feedback om lektionen på Twitter med @sbmaggarwal och @LinuxHint.


