Datavetenskap
Logistisk regression i Python
Logistisk regression är en algoritm för klassificering av maskininlärning. Logistisk regression liknar också linjär regression. Men den största skilln...
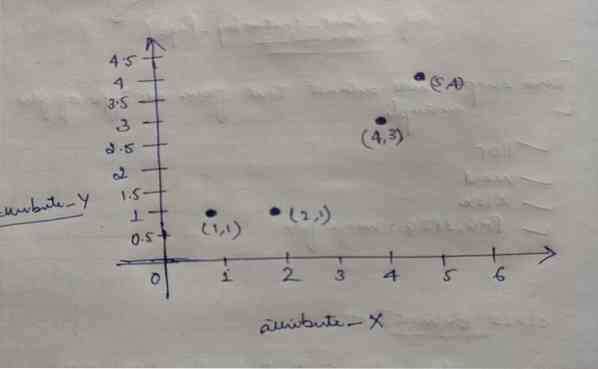
K-medelkluster
Koden för den här bloggen, tillsammans med datasetet, finns på följande länk https: // github.com / shekharpandey89 / k-betyder K-Means-kluster är en ...

Hur man skapar en pivottabell i Pandas Python
I pandas python innehåller pivottabellen summor, räkningar eller aggregeringsfunktioner härledda från en datatabell. Aggregeringsfunktioner kan använd...
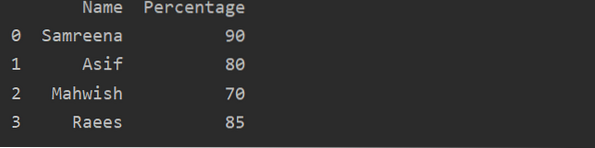
Hur man skapar Pandas DataFrame i Python?
Pandas DataFrame är en 2D (tvådimensionell) kommenterad datastruktur där data är inriktade i tabellform med olika rader och kolumner. För enklare förs...
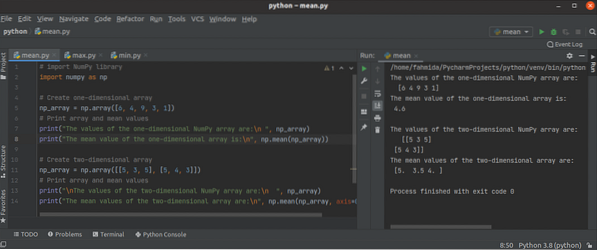
Hur man använder Python NumPy-medelvärdesfunktionerna (), min () och max ()?
Python NumPy-biblioteket har många aggregerade eller statistiska funktioner för att utföra olika typer av uppgifter med den endimensionella eller fler...
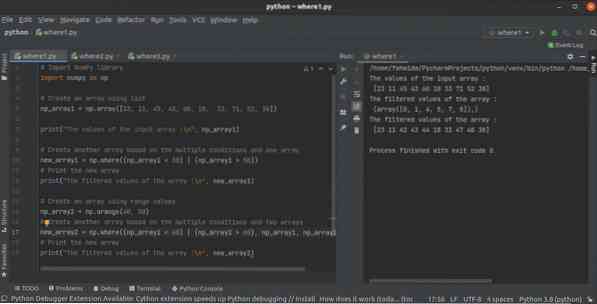
Hur man använder python NumPy där () fungerar med flera förhållanden
NumPy-biblioteket har många funktioner för att skapa arrayen i python. där () -funktionen är en av dem för att skapa en array från en annan NumPy-arra...
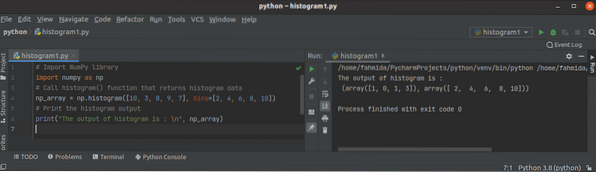
Python NumPy histogram () handledning
Ett histogram är en kartläggning av intervall till frekvenser. Den används för att approximera sannolikhetsdensitetsfunktionen för den specifika varia...
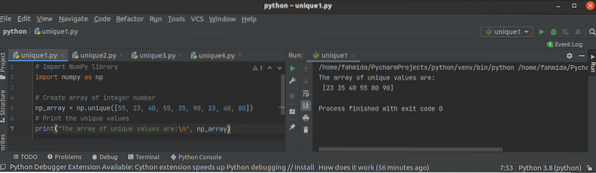
Hur man använder Python NumPy unik () funktion
NumPy-biblioteket används i python för att skapa en eller flera dimensionella matriser, och det har många funktioner att arbeta med arrayen. Den unika...
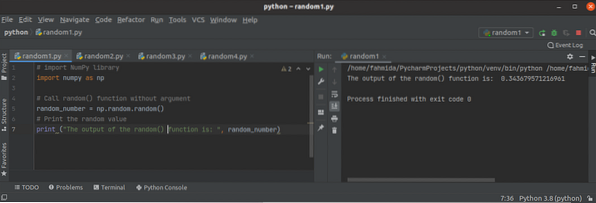
Hur man använder Python NumPy slumpmässig funktion?
När värdet på numret ändras i varje utförande av manuset kallas numret ett slumpmässigt nummer. Slumpmässiga siffror används främst för olika typer av...


