Den översikten är lite abstrakt, så låt oss grunda den i ett verkligt scenario, föreställ dig att du måste övervaka flera webbservrar. Var och en driver sin egen webbplats, och nya loggar genereras ständigt i var och en varje sekund på dagen. Dessutom finns det ett antal mejlservrar som du också behöver övervaka.
Du kan behöva lagra dessa data för bokföring och fakturering, vilket är ett batchjobb som inte kräver omedelbar uppmärksamhet. Du kanske vill köra analyser av data för att fatta beslut i realtid, vilket kräver korrekt och omedelbar inmatning av data. Plötsligt befinner du dig i behovet av att effektivisera data på ett förnuftigt sätt för alla de olika behoven. Kafka fungerar som det lager av abstraktion som flera källor kan publicera olika dataströmmar och ett givet konsument kan prenumerera på de strömmar som den tycker är relevanta. Kafka ser till att uppgifterna är ordnade. Det är internt i Kafka som vi behöver förstå innan vi kommer till ämnet partitionering och nycklar.
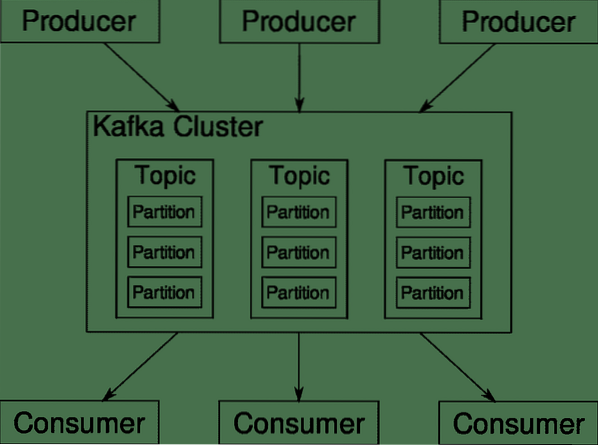
Kafka Ämnen, mäklare och partitioner
Kafka Ämnen är som tabeller i en databas. Varje ämne består av data från en viss källa av en viss typ. Till exempel kan ditt klusterhälsa vara ett ämne som består av CPU- och minnesanvändningsinformation. På samma sätt kan inkommande trafik till hela klustret vara ett annat ämne.
Kafka är utformad för att vara skalbar horisontellt. Det vill säga, en enda instans av Kafka består av flera Kafka mäklare som kör över flera noder kan var och en hantera dataströmmar parallellt med den andra. Även om några av noder misslyckas kan din datapipeline fortsätta att fungera. Ett visst ämne kan sedan delas upp i ett antal partitioner. Denna partitionering är en av de avgörande faktorerna bakom Kafkas horisontella skalbarhet.
Flera olika producenter, datakällor för ett visst ämne, kan skriva till det ämnet samtidigt eftersom var och en skriver till en annan partition, vid varje given punkt. Nu tilldelas vanligtvis data till en partition slumpmässigt, såvida vi inte ger den en nyckel.
Partitionering och beställning
Bara för att sammanfatta, producenter skriver data till ett visst ämne. Det ämnet delas faktiskt upp i flera partitioner. Och varje partition lever oberoende av de andra, även för ett visst ämne. Detta kan leda till mycket förvirring när beställningen till data är viktig. Du kanske behöver dina data i kronologisk ordning, men att ha flera partitioner för din dataström garanterar inte perfekt beställning.
Du kan bara använda en enda partition per ämne, men det besegrar hela syftet med Kafkas distribuerade arkitektur. Så vi behöver någon annan lösning.
Nycklar för partitioner
Data från en producent skickas slumpmässigt till partitioner, som vi nämnde tidigare. Meddelanden är de faktiska bitarna av data. Vad producenter kan göra förutom att bara skicka meddelanden är att lägga till en nyckel som följer med den.
Alla meddelanden som kommer med den specifika nyckeln går till samma partition. Så, till exempel, kan en användares aktivitet spåras kronologiskt om användarens data är taggade med en nyckel och så att de alltid hamnar i en partition. Låt oss kalla den här partitionen p0 och användaren u0.
Partition p0 kommer alltid att hämta de u0-relaterade meddelandena eftersom den nyckeln knyter ihop dem. Men det betyder inte att p0 bara är bunden till det. Det kan också ta upp meddelanden från u1 och u2 om den har kapacitet att göra det. På samma sätt kan andra partitioner konsumera data från andra användare.
Poängen att en given användares data inte sprids över olika partitioner vilket säkerställer kronologisk ordning för den användaren. Men det övergripande ämnet för användardata, kan fortfarande utnyttja Apache Kafkas distribuerade arkitektur.
Slutsats
Medan distribuerade system som Kafka löser några äldre problem som brist på skalbarhet eller att ha en enda felpunkt. De kommer med en uppsättning problem som är unika för sin egen design. Att förutse dessa problem är ett viktigt jobb för alla systemarkitekter. Inte bara det, ibland måste du verkligen göra en kostnads-nyttoanalys för att avgöra om de nya problemen är en värdig avvägning för att bli av med de äldre. Beställning och synkronisering är bara toppen av isberget.
Förhoppningsvis kan artiklar som dessa och den officiella dokumentationen hjälpa dig på vägen.


