Del 1: Ställa in en enda nod
Idag är det både snabbt och enkelt att lagra dina dokument eller data på en lagringsenhet, det är också jämförbart billigt. I bruk är en filnamnreferens som är avsedd att beskriva vad dokumentet handlar om. Alternativt hålls data i ett databashanteringssystem (DBMS) som PostgreSQL, MariaDB eller MongoDB för att bara nämna några alternativ. Flera lagringsmedier är antingen lokalt eller fjärranslutna till datorn, såsom USB-minne, intern eller extern hårddisk, Network Attached Storage (NAS), Cloud Storage eller GPU / Flash-baserad, som i en Nvidia V100 [10].
Däremot är den omvända processen, att hitta rätt dokument i en dokumentsamling, ganska komplex. Det kräver oftast att detekteras filformat utan fel, indexering av dokumentet och extrahering av nyckelbegrepp (dokumentklassificering). Det är här Apache Solr-ramverket kommer in. Det erbjuder ett praktiskt gränssnitt för att göra de nämnda stegen - bygga ett dokumentindex, acceptera sökfrågor, göra den faktiska sökningen och returnera ett sökresultat. Apache Solr utgör således kärnan för effektiv forskning om en databas eller dokumentsilo.
I den här artikeln lär du dig hur Apache Solr fungerar, hur man ställer in en enda nod, indexerar dokument, gör en sökning och hämtar resultatet.
Uppföljningsartiklarna bygger på den här, och i dem diskuterar vi andra, mer specifika användningsfall som att integrera en PostgreSQL DBMS som en datakälla eller belastningsbalansering över flera noder.
Om Apache Solr-projektet
Apache Solr är ett sökmotorverk baserat på den kraftfulla Lucene-sökindexservern [2]. Skrivet i Java underhålls det under paraplyet av Apache Software Foundation (ASF) [6]. Det är fritt tillgängligt under Apache 2-licensen.
Ämnet ”Hitta dokument och data igen” spelar en mycket viktig roll i programvaruvärlden och många utvecklare hanterar det intensivt. Webbplatsen Awesomeopensource [4] listar mer än 150 projekt med öppen källkod för sökmotorer. I början av 2021 är ElasticSearch [8] och Apache Solr / Lucene de två bästa hundarna när det gäller att söka efter större datamängder. Att utveckla din sökmotor kräver mycket kunskap, Frank gör det med det Python-baserade AdvaS Advanced Search [3] -biblioteket sedan 2002.
Konfigurera Apache Solr:
Installationen och driften av Apache Solr är inte komplicerad, det är helt enkelt en hel serie steg som ska utföras av dig. Tillåt cirka 1 timme för resultatet av den första datafrågan. Dessutom är Apache Solr inte bara ett hobbyprojekt utan används också i en professionell miljö. Därför är den valda operativsystemmiljön utformad för långvarig användning.
Som basmiljö för den här artikeln använder vi Debian GNU / Linux 11, som är den kommande Debian-utgåvan (från början av 2021) och förväntas vara tillgänglig i mitten av 2021. För denna handledning förväntar vi oss att du redan har installerat den, antingen som det inbyggda systemet, i en virtuell maskin som VirtualBox eller en AWS-behållare.
Förutom de grundläggande komponenterna behöver du följande programvarupaket installeras på systemet:
- Ringla
- Standard-java
- Libcommons-cli-java
- Libxerces2-java
- Libtika-java (ett bibliotek från Apache Tika-projektet [11])
Dessa paket är standardkomponenter i Debian GNU / Linux. Om du ännu inte har installerat kan du installera dem på en gång som en användare med administrativa rättigheter, till exempel root eller via sudo, som visas enligt följande:
# apt-get install curl default-java libcommons-cli-java libxerces2-java libtika-javaEfter att ha förberett miljön är det andra steget installationen av Apache Solr. Från och med nu är Apache Solr inte tillgängligt som ett vanligt Debian-paket. Därför är det nödvändigt att hämta Apache Solr 8.8 från nedladdningssektionen på projektwebbplatsen [9] först. Använd kommandot wget nedan för att lagra det i / tmp-katalogen i ditt system:
$ wget -O / tmp https: // nedladdningar.apache.org / lucene / solr / 8.8.0 / solr-8.8.0.tgzVäxeln -O förkortar -output-dokumentet och gör att wget lagrar den hämtade tjäran.gz-filen i den angivna katalogen. Arkivet har en storlek på cirka 190 miljoner. Packa sedan upp arkivet i / opt-katalogen med hjälp av tjära. Som ett resultat hittar du två underkataloger - / opt / solr och / opt / solr-8.8.0, medan / opt / solr är inställd som en symbolisk länk till den senare. Apache Solr levereras med ett installationsskript som du kör nästa, det är som följer:
# / opt / solr-8.8.0 / bin / install_solr_service.shDetta resulterar i skapandet av Linux-användaren solr körs i Solr-tjänsten plus hans hemkatalog under / var / solr etablerar Solr-tjänsten, läggs till med motsvarande noder och startar Solr-tjänsten på port 8983. Dessa är standardvärdena. Om du inte är nöjd med dem kan du ändra dem under installationen eller till och med senare eftersom installationsskriptet accepterar motsvarande växlar för inställningsjusteringar. Vi rekommenderar att du tittar på Apache Solr-dokumentationen angående dessa parametrar.
Solr-programvaran är organiserad i följande kataloger:
- soptunna
innehåller Solr-binärer och filer för att köra Solr som en tjänst - bidrag
externa Solr-bibliotek som dataimporthanterare och Lucene-biblioteken - dist
interna Solr-bibliotek - docs
länk till Solr-dokumentationen tillgänglig online - exempel
exempeluppsättningar eller flera användningsfall / scenarier - licenser
mjukvarulicenser för de olika Solr-komponenterna - server
serverkonfigurationsfiler, såsom server / etc för tjänster och portar
Mer detaljerat kan du läsa om dessa kataloger i Apache Solr-dokumentationen [12].
Hantera Apache Solr:
Apache Solr körs som en tjänst i bakgrunden. Du kan starta den på två sätt, antingen med systemctl (första raden) som en användare med administrativa behörigheter eller direkt från Solr-katalogen (andra raden). Vi listar båda terminalkommandona nedan:
# systemctl start solr$ solr / bin / solr start
Att stoppa Apache Solr görs på samma sätt:
# systemctl stopp solr$ solr / bin / solr stop
Samma sätt går att starta om Apache Solr-tjänsten:
# systemctl starta om solr$ solr / bin / solr starta om
Dessutom kan statusen för Apache Solr-processen visas enligt följande:
# systemctl status solr$ solr / bin / solr status
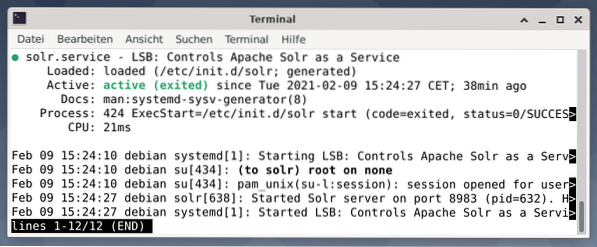
Utgången listar den servicefil som startades, både motsvarande tidsstämpel och loggmeddelanden. Figuren nedan visar att Apache Solr-tjänsten startades på port 8983 med process 632. Processen körs framgångsrikt i 38 minuter.
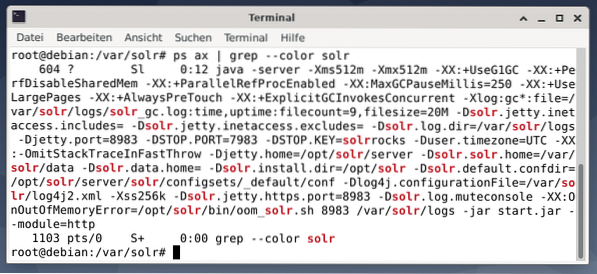
För att se om Apache Solr-processen är aktiv kan du också korsa kontrollen med kommandot ps i kombination med grep. Detta begränsar ps-utdata till alla Apache Solr-processer som för närvarande är aktiva.
# ps ax | grep - färg solrFiguren nedan visar detta för en enda process. Du ser Java-samtalet som åtföljs av en lista med parametrar, till exempel minnesanvändning (512M) för att lyssna på 8983 för frågor, 7983 för stoppförfrågningar och typ av anslutning (http).
Lägga till användare:
Apache Solr-processerna körs med en specifik användare med namnet solr. Den här användaren hjälper till att hantera Solr-processer, ladda upp data och skicka förfrågningar. Vid installationen har användarens solr inte ett lösenord och förväntas ha ett att logga in för att gå vidare. Ställ in ett lösenord för användaren solr som användarrot, det visas på följande sätt:
# passwd solrSolr-administration:
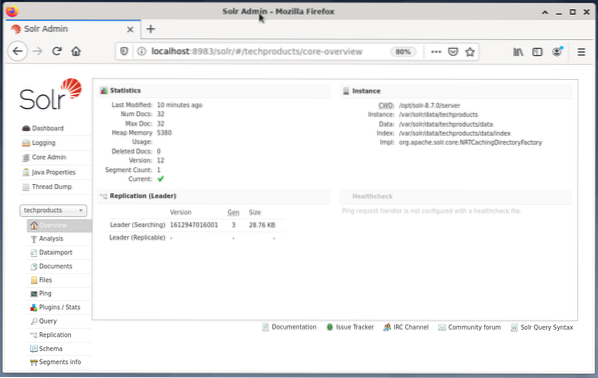
Hantera Apache Solr görs med hjälp av Solr Dashboard. Detta är tillgängligt via webbläsare från http: // localhost: 8983 / solr. Figuren nedan visar huvudvyn.
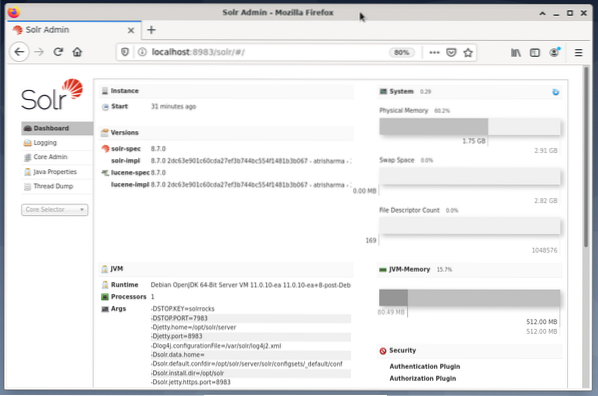
Till vänster ser du huvudmenyn som leder dig till underavsnitten för loggning, administration av Solr-kärnor, Java-installation och statusinformation. Välj önskad kärna med hjälp av markeringsrutan under menyn. Till höger om menyn visas motsvarande information. Instrumentpanelens menypost visar ytterligare information om Apache Solr-processen, samt aktuell belastning och minnesanvändning.
Observera att innehållet på instrumentpanelen ändras beroende på antalet Solr-kärnor och de dokument som har indexerats. Ändringar påverkar både menyalternativen och motsvarande information som syns till höger.
Förstå hur sökmotorer fungerar:
Enkelt sagt analyserar sökmotorer dokument, kategoriserar dem och låter dig göra en sökning baserat på deras kategorisering. I grund och botten består processen av tre steg, som kallas genomsökning, indexering och rangordning [13].
Krypande är det första steget och beskriver en process genom vilken nytt och uppdaterat innehåll samlas in. Sökmotorn använder robotar som också kallas spindlar eller sökrobotar, därav termen genomsökning för att gå igenom tillgängliga dokument.
Den andra etappen kallas indexering. Det tidigare samlade innehållet görs sökbart genom att förvandla originaldokumenten till ett format som sökmotorn förstår. Nyckelord och begrepp extraheras och lagras i (massiva) databaser.
Den tredje etappen kallas ranking och beskriver processen att sortera sökresultaten utifrån deras relevans med en sökfråga. Det är vanligt att resultaten visas i fallande ordning så att resultatet som har störst relevans för sökarens fråga kommer först.
Apache Solr fungerar på samma sätt som den tidigare beskrivna trestegsprocessen. Liksom den populära sökmotorn Google använder Apache Solr en sekvens av att samla, lagra och indexera dokument från olika källor och gör dem tillgängliga / sökbara i nästan realtid.
Apache Solr använder olika sätt att indexera dokument inklusive följande [14]:
- Använda en Index Request Handler när du laddar upp dokumenten direkt till Solr. Dessa dokument ska vara i JSON-, XML / XSLT- eller CSV-format.
- Använda Extracting Request Handler (Solr Cell). Dokumenten ska vara i PDF- eller Office-format, som stöds av Apache Tika.
- Med hjälp av Data Import Handler, som förmedlar data från en databas och katalogiserar dem med hjälp av kolumnnamn. Dataimporthanteraren hämtar data från e-post, RSS-flöden, XML-data, databaser och vanliga textfiler som källor.
En fråghanterare används i Apache Solr när en sökbegäran skickas. Frågehanteraren analyserar den givna frågan baserat på samma koncept som indexhanteraren för att matcha frågan och tidigare indexerade dokument. Matcherna rankas efter deras lämplighet eller relevans. Nedan visas ett kort exempel på frågor.
Ladda upp dokument:
För enkelhets skull använder vi ett exempel på dataset för följande exempel som redan tillhandahålls av Apache Solr. Uppladdning av dokument görs som användaren. Steg 1 är skapandet av en kärna med namnet techproducts (för ett antal tech-artiklar).
$ solr / bin / solr skapa -c techproducts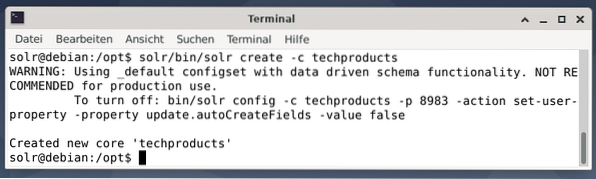
Allt är bra om du ser meddelandet “Skapad ny kärna” techproducts ””. Steg 2 är att lägga till data (XML-data från exampledocs) till de tidigare skapade kärnteknologiprodukterna. Verktygsposten används som parametreras av -c (kärnans namn) och de dokument som ska laddas upp.
$ solr / bin / post -c techproducts solr / exempel / exampledocs / *.xmlDetta kommer att resultera i utdata som visas nedan och kommer att innehålla hela samtalet plus de 14 dokument som har indexerats.
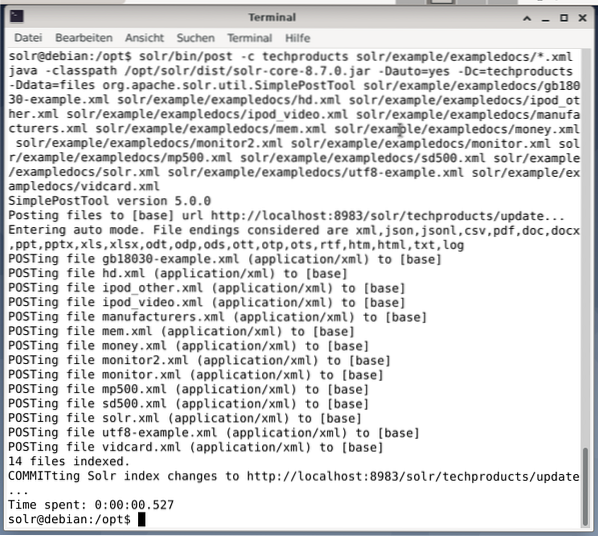
Dashboard visar också ändringarna. En ny post med namnet techproducts är synlig i rullgardinsmenyn till vänster och antalet motsvarande dokument har ändrats på höger sida. Tyvärr är en detaljerad vy av de råa datauppsättningarna inte möjlig.
Om kärnan / samlingen måste tas bort, använd följande kommando:
$ solr / bin / solr delete -c techproductsFrågedata:
Apache Solr erbjuder två gränssnitt för att fråga data: via den webbaserade instrumentpanelen och kommandoraden. Vi kommer att förklara båda metoderna nedan.
Skicka frågor via Solr-instrumentpanelen görs enligt följande:
- Välj nodteknologiprodukter från rullgardinsmenyn.
- Välj posten Fråga från menyn under rullgardinsmenyn.
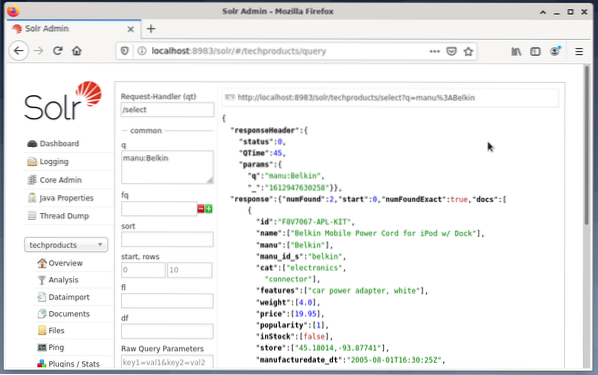
Inmatningsfält dyker upp på höger sida för att formulera frågan som begäranhanterare (qt), fråga (q) och sorteringsordning (sortering). - Välj inmatningsfältet Fråga och ändra innehållet i posten från “*: *” till “manu: Belkin”. Detta begränsar sökningen från "alla fält med alla poster" till "datamängder som har namnet Belkin i manufältet". I det här fallet förkortar namnet manu tillverkaren i exemplet datamängden.
- Tryck sedan på knappen med Kör fråga. Resultatet är en utskriven HTTP-begäran ovanpå och ett resultat av sökfrågan i JSON-dataformat nedan.
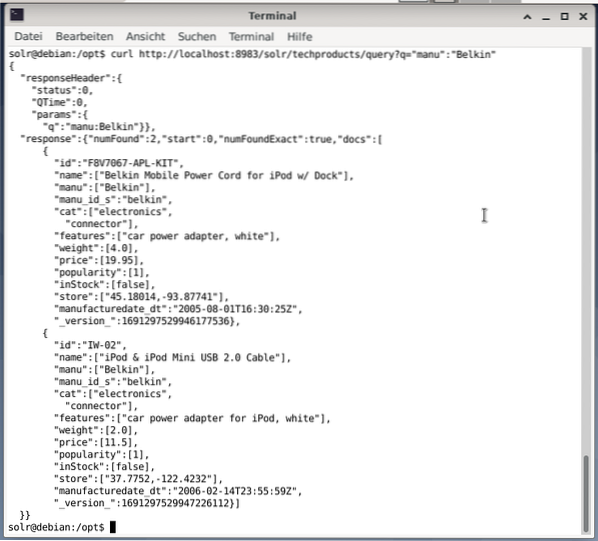
Kommandoraden accepterar samma fråga som i instrumentpanelen. Skillnaden är att du måste veta namnet på frågefälten. För att skicka samma fråga som ovan måste du köra följande kommando i en terminal:
$ curlhttp: // localhost: 8983 / solr / techproducts / fråga?q = ”manu”: ”Belkin
Utgången är i JSON-format, som visas nedan. Resultatet består av en svarsrubrik och det faktiska svaret. Svaret består av två datamängder.
Avslutar:
Grattis! Du har uppnått den första etappen med framgång. Den grundläggande infrastrukturen är inställd och du har lärt dig hur du laddar upp och frågar efter dokument.
Nästa steg kommer att täcka hur man kan förfina frågan, formulera mer komplexa frågor och förstå de olika webbformulär som tillhandahålls av Apache Solr-frågesidan. Vi kommer också att diskutera hur man efterbearbetar sökresultatet med olika utdataformat som XML, CSV och JSON.
Om Författarna:
Jacqui Kabeta är miljöaktivist, ivrig forskare, tränare och mentor. I flera afrikanska länder har hon arbetat inom IT-industrin och NGO-miljöer.
Frank Hofmann är IT-utvecklare, tränare och författare och föredrar att arbeta från Berlin, Genève och Kapstaden. Medförfattare till Debian Package Management Book tillgänglig från dpmb.org
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Lucene Search Library, https: // lucene.apache.org /
- [3] AdvaS Advanced Search, https: // pypi.org / project / AdvaS-Advanced-Search /
- [4] De 165 bästa sökmotorn Open Source-projekt, https: // awesomeopensource.com / projekt / sökmotor
- [5] ElasticSearch, https: // www.elastisk.co / de / elasticsearch /
- [6] Apache Software Foundation (ASF), https: // www.apache.org /
- [7] FESS, https: // fess.codelibs.org / index.html
- [8] ElasticSearch, https: // www.elastisk.koda/
- [9] Apache Solr, sektion för nedladdning, https: // lucene.apache.org / solr / nedladdningar.htm
- [10] Nvidia V100, https: // www.nvidia.com / en-us / datacenter / v100 /
- [11] Apache Tika, https: // tika.apache.org /
- [12] Apache Solr-kataloglayout, https: // lucene.apache.org / solr / guide / 8_8 / installation-solr.html # katalog-layout
- [13] Hur sökmotorer fungerar: Genomsökning, indexering och rangordning. Nybörjarguiden för SEO https: // moz.com / nybörjarguide-till-seo / hur-sökmotorer fungerar
- [14] Kom igång med Apache Solr, https: // sematext.com / guides / solr / #: ~: text = Solr% 20works% 20by% 20gathering% 2C% 20storing, med% 20huge% 20volumes% 20of% 20data


