Den här artikeln kommer att diskutera några av sätten att genomsöka en webbplats, inklusive verktyg för webbgenomsökning och hur man använder dessa verktyg för olika funktioner. Verktygen som diskuteras i den här artikeln inkluderar:
- HTTrack
- Cyotek WebCopy
- Content Grabber
- ParseHub
- OutWit Hub
HTTrack
HTTrack är en gratis programvara med öppen källkod som används för att ladda ner data från webbplatser på internet. Det är en lättanvänd programvara utvecklad av Xavier Roche. Den nedladdade informationen lagras på localhost i samma struktur som på den ursprungliga webbplatsen. Proceduren för att använda detta verktyg är som följer:
Installera först HTTrack på din maskin genom att köra följande kommando:
[e-postskyddad]: ~ $ sudo apt-get install httrackEfter installation av programvaran, kör följande kommando för att genomsöka webbplatsen. I följande exempel kommer vi att genomsöka linuxhint.com:
[e-postskyddad]: ~ $ httrack http: // www.linuxhint.com -o ./Ovanstående kommando hämtar all data från webbplatsen och sparar den i den aktuella katalogen. Följande bild beskriver hur man använder httrack:
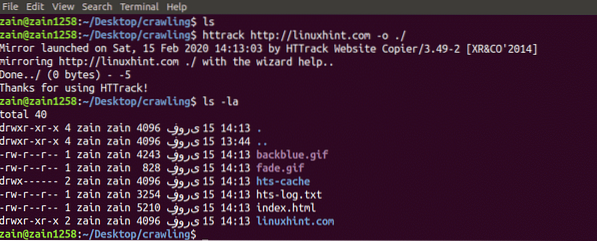
Från figuren kan vi se att data från webbplatsen har hämtats och sparats i den aktuella katalogen.
Cyotek WebCopy
Cyotek WebCopy är en gratis webbgenomsökningsprogramvara som används för att kopiera innehåll från en webbplats till localhost. Efter att ha kört programmet och tillhandahållit webbplatsens länk och målmapp kommer hela webbplatsen att kopieras från angiven URL och sparas i localhost. Ladda ner Cyotek WebCopy från följande länk:
https: // www.cyotek.com / cyotek-webcopy / nedladdningar
Efter installationen, när webbsökaren körs, visas fönstret nedan:
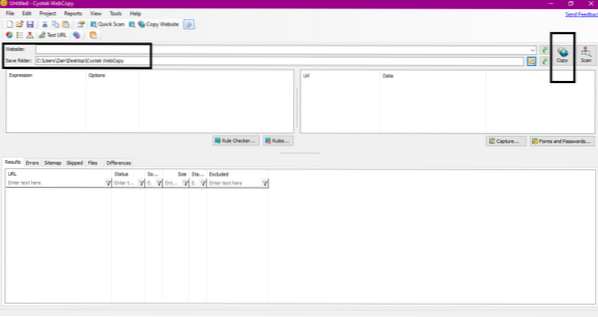
När du anger webbadressen till webbplatsen och anger destinationsmappen i de obligatoriska fälten, klicka på kopia för att börja kopiera data från webbplatsen, som visas nedan:
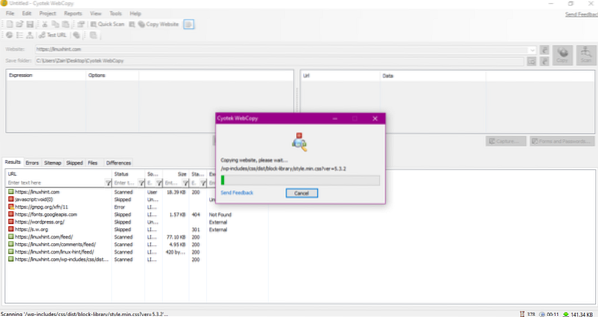
Efter att ha kopierat data från webbplatsen, kontrollera om data har kopierats till målkatalogen enligt följande:
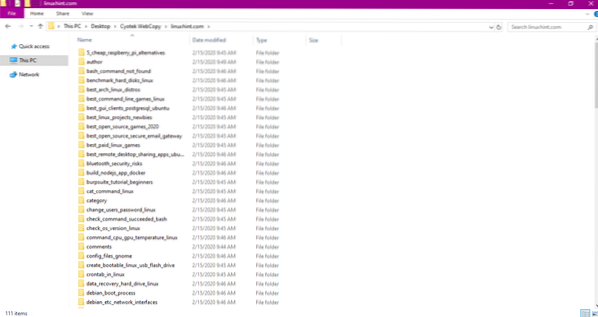
I bilden ovan har all data från webbplatsen kopierats och sparats på målplatsen.
Content Grabber
Content Grabber är ett molnbaserat program som används för att extrahera data från en webbplats. Det kan extrahera data från alla webbplatser med flera strukturer. Du kan ladda ner Content Grabber från följande länk
http: // www.tucuer.com / förhandsvisning / 1601497 / Content-Grabber
Efter installation och körning av programmet visas ett fönster, som visas i följande bild:
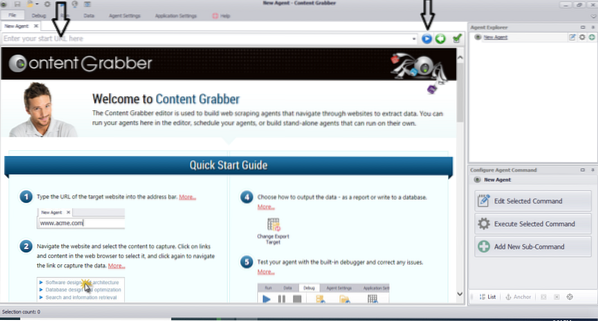
Ange webbadressen till webbplatsen som du vill extrahera data från. När du har angett webbadressen till webbplatsen väljer du det element du vill kopiera enligt nedan:
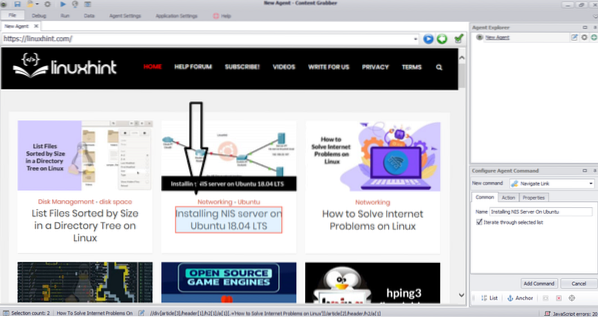
När du har valt önskat element, börja kopiera data från webbplatsen. Detta ska se ut som följande bild:
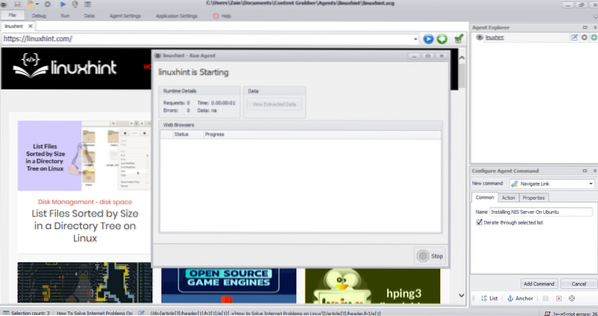
Data som extraheras från en webbplats sparas som standard på följande plats:
C: \ Användare \ användarnamn \ Dokument \ Content GrabberParseHub
ParseHub är ett gratis och lättanvänt webbgenomsökningsverktyg. Detta program kan kopiera bilder, text och andra former av data från en webbplats. Klicka på följande länk för att ladda ner ParseHub:
https: // www.parsehub.com / snabbstart
Efter nedladdning och installation av ParseHub, kör programmet. Ett fönster visas, som visas nedan:
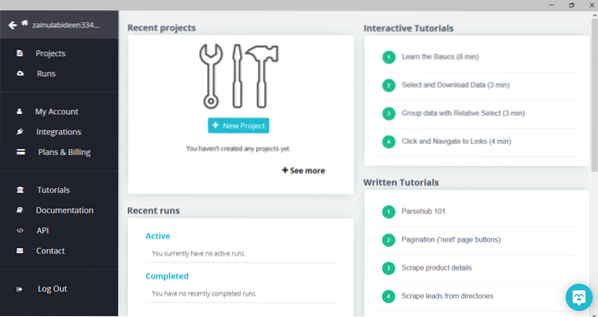
Klicka på "Nytt projekt", ange webbadressen i adressfältet på webbplatsen som du vill extrahera data från och tryck på enter. Klicka sedan på “Starta projekt på den här webbadressen.”
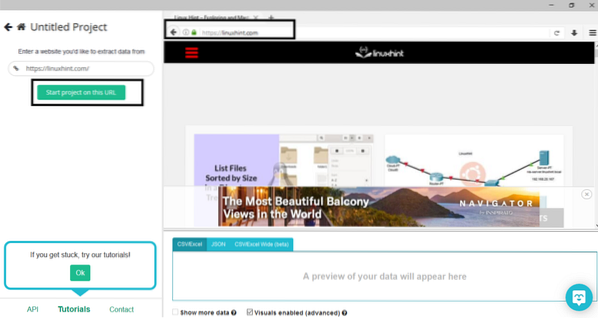
När du har valt önskad sida klickar du på "Hämta data" till vänster för att genomsöka webbsidan. Följande fönster visas:
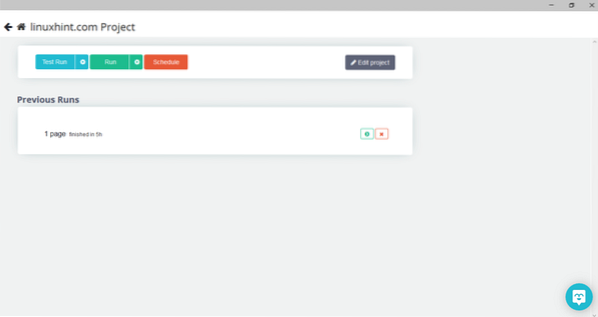
Klicka på "Kör" så kommer programmet att be om den datatyp du vill ladda ner. Välj önskad typ så kommer programmet att fråga efter målmappen. Spara slutligen data i målkatalogen.
OutWit Hub
OutWit Hub är en webbsökare som används för att extrahera data från webbplatser. Detta program kan extrahera bilder, länkar, kontakter, data och text från en webbplats. De enda stegen som krävs är att ange webbadressen till webbplatsen och välja datatyp som ska extraheras. Ladda ner denna programvara från följande länk:
https: // www.överlista.com / produkter / nav /
Efter installation och körning av programmet visas följande fönster:
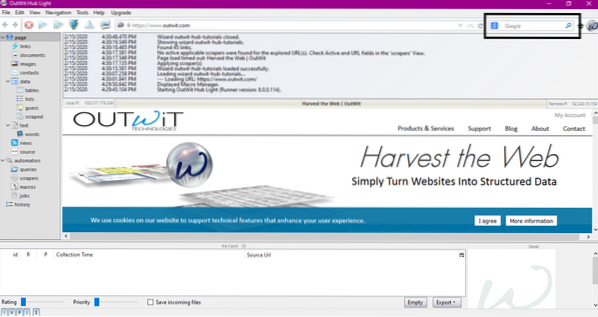
Ange webbadressen till webbplatsen i fältet som visas i bilden ovan och tryck på enter. Fönstret visar webbplatsen, som visas nedan:
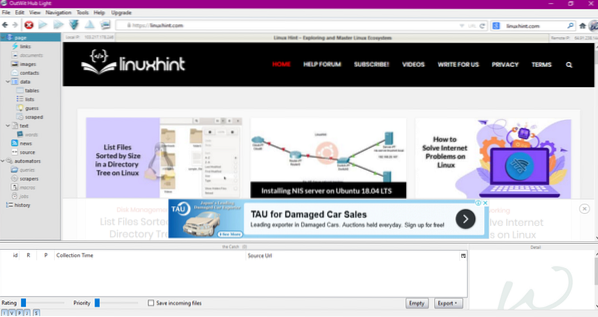
Välj datatypen du vill extrahera från webbplatsen från den vänstra panelen. Följande bild illustrerar denna process exakt:
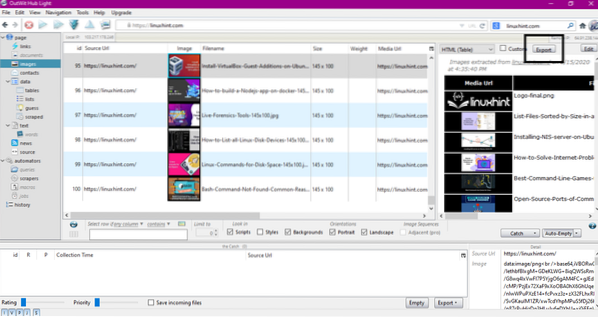
Välj nu den bild du vill spara på localhost och klicka på exportknappen markerad i bilden. Programmet kommer att be om målkatalogen och spara data i katalogen.
Slutsats
Webbsökare används för att extrahera data från webbplatser. Denna artikel diskuterade några webbgenomsökningsverktyg och hur man använder dem. Användningen av varje webbsökare diskuterades steg för steg med siffror vid behov. Jag hoppas att efter att ha läst den här artikeln, kommer du att ha det enkelt att använda dessa verktyg för att genomsöka en webbplats.


