TensorFlow har funnit enorm användning inom maskininlärning, just för att maskininlärning involverar en hel del siffror och används som en allmän problemlösningsteknik. Och även om vi kommer att interagera med den med hjälp av Python, har den frontend för andra språk som Go, Node.js och till och med C #.
Tensorflow är som en svart ruta som döljer alla matematiska finesser i den och utvecklaren ringer bara rätt funktioner för att lösa ett problem. Men vilket problem?
Maskininlärning (ML)
Antag att du utformar en bot för att spela schack. På grund av hur schack är utformat, hur bitarna rör sig och det väldefinierade syftet med spelet är det mycket möjligt att skriva ett program som skulle spela spelet extremt bra. I själva verket skulle det överlista hela mänskligheten i schack. Det skulle veta exakt vilket drag det behöver göra med tanke på alla delar på brädet.
Ett sådant program kan dock bara spela schack. Spelets regler är inbakade i kodens logik och allt som programmet gör är att utföra den logiken noggrant och mer exakt än någon människa kunde. Det är inte en algoritm för allmänt ändamål som du kan använda för att utforma vilken spelbot som helst.
Med maskininlärning förändras paradigmet och algoritmerna blir mer och mer allmänna.
Idén är enkel, den börjar med att definiera ett klassificeringsproblem. Till exempel vill du automatisera processen för att identifiera arter av spindlar. De arter som är kända för dig är de olika klasserna (inte förväxlas med taxonomiska klasser) och syftet med algoritmen är att sortera en ny okänd bild i en av dessa klasser.
Här skulle det första steget för människan vara att bestämma funktionerna hos olika enskilda spindlar. Vi skulle tillhandahålla data om längd, bredd, kroppsmassa och färg på enskilda spindlar tillsammans med arten de tillhör:
| Längd | Bredd | Massa | Färg | Textur | Arter |
| 5 | 3 | 12 | Brun | slät | Pappa Långben |
| 10 | 8 | 28 | Brun svart | hårig | Tarantel |
Att ha en stor samling av sådana individuella spindeldata kommer att användas för att "träna" algoritmen och en annan liknande dataset kommer att användas för att testa algoritmen för att se hur bra det gör mot ny information som det aldrig har stött på tidigare, men som vi redan känner till svara på.
Algoritmen startar på ett slumpmässigt sätt. Det vill säga att varje spindel oavsett dess egenskaper skulle klassificeras som någon av arten. Om det finns 10 olika arter i vår dataset, skulle denna naiva algoritm ges rätt klassificering ungefär 1/10 av tiden på grund av ren tur.
Men då började maskininlärningsaspekten ta över. Det skulle börja associera vissa funktioner med ett visst resultat. Till exempel är håriga spindlar sannolikt tarantula, och det är de större spindlarna också. Så närhelst, en ny spindel som är stor och hårig dyker upp, kommer den att tilldelas en högre sannolikhet att vara tarantula. Observera att vi fortfarande arbetar med sannolikheter, det beror på att vi i sig arbetar med en sannolik algoritm.
Inlärningsdelen fungerar genom att ändra sannolikheterna. Inledningsvis börjar algoritmen med att slumpmässigt tilldela en "art" -etikett till individer genom att göra slumpmässiga korrelationer som att vara "håriga" och vara "pappa långa ben". När det gör en sådan korrelation och träningsdatasetet inte verkar överens med det, tappas antagandet.
På liknande sätt, när en korrelation fungerar bra genom flera exempel, blir den starkare varje gång. Denna metod för att snubbla mot sanningen är anmärkningsvärt effektiv tack vare många matematiska finesser som du som nybörjare inte vill oroa dig för.
TensorFlow och träna din egen Flower Classifier
TensorFlow tar tanken på maskininlärning ännu längre. I exemplet ovan var du ansvarig för att bestämma de funktioner som skiljer en spindel från en annan. Vi var tvungna att mäta enskilda spindlar noggrant och skapa hundratals sådana poster.
Men vi kan göra bättre, genom att bara tillhandahålla rå bilddata till algoritmen kan vi låta algoritmen hitta mönster och förstå olika saker om bilden som att känna igen formerna i bilden och sedan förstå vad strukturen på olika ytor är, färgen , och så vidare. Detta är början om datorvision och du kan använda den för andra ingångar, som ljudsignaler och träna din algoritm för röstigenkänning. Allt detta kommer under paraplybegreppet "Deep Learning" där maskininlärning tas till sin logiska ytterlighet.
Denna generaliserade uppsättning begrepp kan sedan specialiseras när man hanterar många bilder av blommor och kategoriserar dem.
I exemplet nedan använder vi en Python2.7 front-end för gränssnitt med TensorFlow och vi kommer att använda pip (inte pip3) för att installera TensorFlow. Python 3-stödet är fortfarande lite buggy.
För att skapa din egen bildklassificering, använd TensorFlow först, låt oss installera den med pip:
$ pip installera tensorflowDärefter måste vi klona tensorflow-för-poeter-2 git-förvar. Det här är ett riktigt bra ställe att börja av två skäl:
- Det är enkelt och lätt att använda
- Den kommer förutbildad till en viss grad. Till exempel är blommaklassificatorn redan utbildad för att förstå vilken struktur den tittar på och vilka former den tittar på så att den är beräkningsmässigt mindre intensiv.
Låt oss få förvaret:
$ git-klon https: // github.com / googlecodelabs / tensorflow-for-poets-2$ cd tensorflow-för-poeter-2
Detta kommer att bli vår arbetskatalog, så alla kommandon bör utfärdas inifrån den, från och med nu.
Vi behöver fortfarande träna algoritmen för det specifika problemet med att känna igen blommor, för det behöver vi träningsdata, så låt oss få det:
$ curl http: // nedladdning.tensorflöde.org / example_images / flower_photos.tgz| tjära xz -C tf_files
Katalogen .. ./tensorflow-for-poets-2 / tf_files innehåller massor av dessa bilder korrekt märkta och redo att användas. Bilderna kommer att vara för två olika ändamål:
- Utbildning av ML-programmet
- Testa ML-programmet
Du kan kontrollera innehållet i mappen tf_files och här kommer du att upptäcka att vi bara minskar till endast fem kategorier av blommor, nämligen prästkragar, tulpaner, solrosor, maskros och rosor.
Träna modellen
Du kan starta träningsprocessen genom att först ställa in följande konstanter för att ändra storlek på alla inmatade bilder till en standardstorlek och med hjälp av en lätt mobilarkitektur:
$ IMAGE_SIZE = 224$ ARCHITECTURE = "mobilenet_0.50 _ $ IMAGE_SIZE "
Anropa sedan python-skriptet genom att köra kommandot:
$ python -m-skript.omskola \--flaskhals_dir = tf_filer / flaskhalsar \
--how_many_training_steps = 500 \
--modell_dir = tf_filer / modeller / \
--summaries_dir = tf_files / training_summaries / "$ ARCHITECTURE" \
--output_graph = tf_files / retrained_graph.pb \
--output_labels = tf_files / retrained_labels.Text \
--arkitektur = "$ ARCHITECTURE" \
--image_dir = tf_files / flower_photos
Även om det finns många alternativ som specificeras här, de flesta av dem anger dina inmatningsdatakataloger och antalet iteration, samt utdatafiler där informationen om den nya modellen skulle lagras. Det tar inte längre än 20 minuter att köra på en medelmåttig bärbar dator.
När manuset har avslutat både träning och testning ger det en noggrannhetsuppskattning av den utbildade modellen, som i vårt fall var något högre än 90%.
Använda den utbildade modellen
Du är nu redo att använda den här modellen för bildigenkänning av varje ny bild av en blomma. Vi kommer att använda den här bilden:

Solrosens ansikte är knappt synlig och detta är en stor utmaning för vår modell:
För att få den här bilden från Wikimedia commons, använd wget:
$ wget https: // uppladdning.wikimedia.org / wikipedia / commons / 2/28 / Sunflower_head_2011_G1.jpg$ mv Sunflower_head_2011_G1.jpg tf_files / okänd.jpg
Det sparas som okänd.jpg under tf_files underkatalog.
För sanningens ögonblick ska vi se vad vår modell har att säga om den här bilden.För att göra det åberopar vi label_image manus:
$ python -m-skript.label_image --graph = tf_files / retrained_graph.pb --image = tf_files / okänd.jpg
Du skulle få en utgång liknande den här:
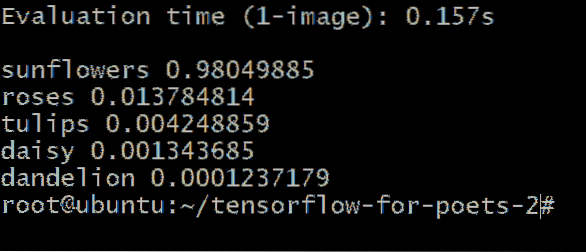
Siffrorna bredvid blomtypen representerar sannolikheten att vår okända bild tillhör den kategorin. Till exempel är det 98.04% är säkra på att bilden är av en solros och att den bara är 1.37% chans att det blir en ros.
Slutsats
Även med mycket medelmåttiga beräkningsresurser ser vi en svimlande noggrannhet vid identifiering av bilder. Detta visar tydligt kraften och flexibiliteten hos TensorFlow.
Härifrån kan du börja experimentera med olika andra typer av ingångar eller försöka börja skriva din egen applikation med Python och TensorFlow. Om du vill veta det inre arbetet med maskininlärning lite bättre här är ett interaktivt sätt för dig att göra det.


