Den här artikeln visar hur du hittar dubbletter i data och tar bort dubbletter med Pandas Python-funktioner.
I den här artikeln har vi tagit en datamängd över befolkningen i olika stater i USA, som finns i en .csv-filformat. Vi kommer att läsa .csv-fil för att visa det ursprungliga innehållet i den här filen, enligt följande:
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
skriva ut (df_state)
I följande skärmdump kan du se det dubbla innehållet i den här filen:
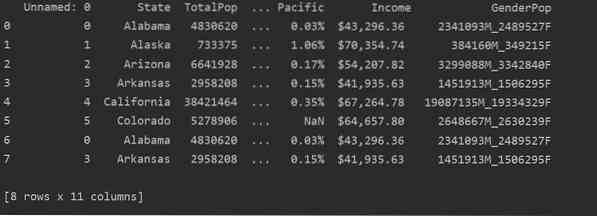
Identifiera duplikat i Pandas Python
Det är nödvändigt att avgöra om de data du använder har duplicerade rader. För att söka efter dataduplicering kan du använda någon av metoderna i följande avsnitt.
Metod 1:
Läs csv-filen och skicka den till dataramen. Identifiera sedan de dubbla raderna med duplicerad () fungera. Slutligen, använd utskriftsuttrycket för att visa de dubbla raderna.
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplicerad ()]
skriv ut ("\ n \ nDuplicera rader: \ n ".format (Dup_Rows))
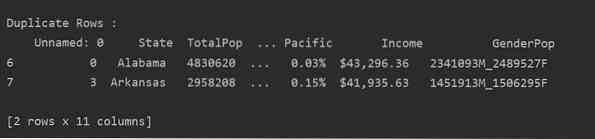
Metod 2:
Med den här metoden kan är_duplicerad kolumnen kommer att läggas till i slutet av tabellen och markeras som "True" när det gäller dubblerade rader.
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
df_state ["is_duplicate"] = df_state.duplicerad ()
skriva ut ("\ n ".format (df_state))
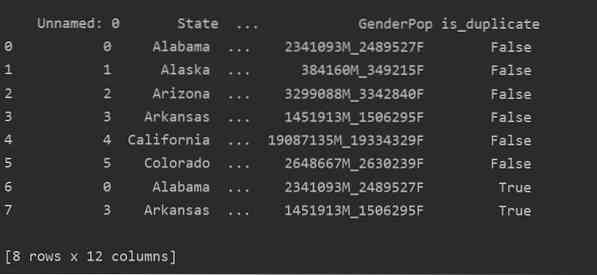
Släppa dubbletter i Pandas Python
Duplicerade rader kan tas bort från din dataram med följande syntax:
drop_duplicates (subset = ", keep =", inplace = False)
Ovanstående tre parametrar är valfria och förklaras mer detaljerat nedan:
ha kvar: den här parametern har tre olika värden: First, Last och False. Det första värdet behåller den första förekomsten och tar bort efterföljande dubbletter, det sista värdet behåller bara den senaste förekomsten och tar bort alla tidigare dubbletter, och det falska värdet tar bort alla duplicerade rader.
delmängd: etikett som används för att identifiera de duplicerade raderna
på plats: innehåller två villkor: sant och falskt. Den här parametern tar bort dubblerade rader om den är inställd på True.
Ta bort dubbletter som bara håller första gången
När du använder "keep = first" behålls bara förekomsten av den första raden och alla andra dubbletter tas bort.
Exempel
I det här exemplet behålls endast den första raden och de återstående dubbletterna raderas:
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplicerad ()]
skriv ut ("\ n \ nDuplicera rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'first')
skriv ut ('\ n \ nResult DataFrame efter dubblett borttagning: \ n', DF_RM_DUP.huvud (n = 5))
I följande skärmdump markeras den kvarhållna första raden i rött och de återstående dubbleringarna tas bort:
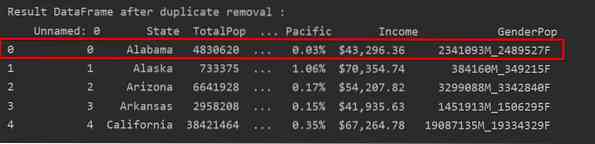
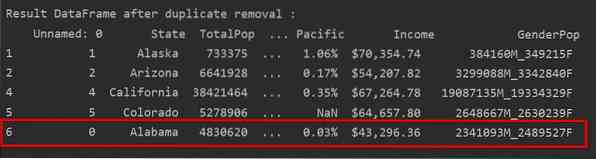
Ta bort dubbletter som bara håller den senaste förekomsten
När du använder "keep = last" tas alla dubbletterader utom den senaste förekomsten bort.
Exempel
I följande exempel tas alla duplicerade rader bort förutom endast den senaste förekomsten.
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplicerad ()]
skriv ut ("\ n \ nDuplicera rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = 'last')
skriv ut ('\ n \ nResultat DataFrame efter dubblett borttagning: \ n', DF_RM_DUP.huvud (n = 5))
I följande bild tas duplikaten bort och endast den sista raden förekommer:
Ta bort alla duplicerade rader
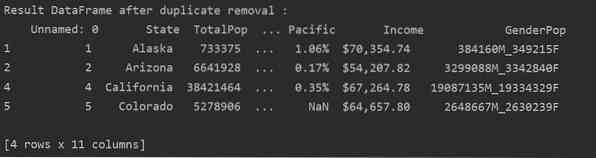
För att ta bort alla dubbla rader från en tabell, ställ in “keep = False” enligt följande:
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplicerad ()]
skriv ut ("\ n \ nDuplicera rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (keep = False)
skriv ut ('\ n \ nResult DataFrame efter dubblett borttagning: \ n', DF_RM_DUP.huvud (n = 5))
Som du kan se i följande bild tas alla dubbletter bort från dataramen:
Ta bort relaterade duplikat från en angiven kolumn
Som standard kontrollerar funktionen efter alla duplicerade rader från alla kolumner i den angivna dataramen. Men du kan också ange kolumnnamnet genom att använda delmängdsparametern.
Exempel
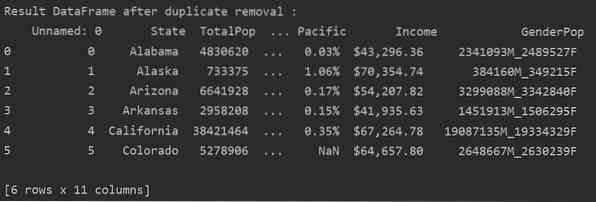
I följande exempel tas alla relaterade dubbletter bort från kolumnen 'Stater'.
importera pandor som pddf_state = pd.read_csv ("C: / Users / DELL / Desktop / population_ds.csv ")
Dup_Rows = df_state [df_state.duplicerad ()]
skriv ut ("\ n \ nDuplicera rader: \ n ".format (Dup_Rows))
DF_RM_DUP = df_stat.drop_duplicates (subset = 'State')
skriv ut ('\ n \ nResult DataFrame efter dubblett borttagning: \ n', DF_RM_DUP.huvud (n = 6))
Slutsats
Den här artikeln visade dig hur du tar bort dubblerade rader från en dataram med hjälp av drop_duplicates () funktion i Pandas Python. Du kan också rensa dina data för duplicering eller redundans med den här funktionen. Artikeln visade dig också hur du identifierar dubbletter i din dataram.


