Apache Hadoop är en stor datalösning för lagring och analys av stora mängder data. I den här artikeln kommer vi att beskriva de komplexa installationsstegen för Apache Hadoop för att komma igång med det på Ubuntu så snabbt som möjligt. I det här inlägget installerar vi Apache Hadoop på en Ubuntu 17.10 maskin.
Ubuntu-version
För den här guiden använder vi Ubuntu version 17.10 (GNU / Linux 4.13.0-38-generisk x86_64).
Uppdaterar befintliga paket
För att starta installationen för Hadoop är det nödvändigt att vi uppdaterar vår maskin med de senaste tillgängliga programvarupaket. Vi kan göra detta med:
sudo apt-get update && sudo apt-get -y dist-upgradeEftersom Hadoop är baserat på Java måste vi installera det på vår maskin. Vi kan använda vilken Java-version som helst ovanför Java 6. Här kommer vi att använda Java 8:
sudo apt-get -y installera openjdk-8-jdk-headlessHämtar Hadoop-filer
Alla nödvändiga paket finns nu på vår maskin. Vi är redo att ladda ner de nödvändiga Hadoop TAR-filerna så att vi kan börja ställa in dem och köra ett exempelprogram med Hadoop också.
I den här guiden kommer vi att installera Hadoop v3.0.1. Ladda ner motsvarande filer med det här kommandot:
wget http: // spegel.cc.columbia.edu / pub / programvara / apache / hadoop / common / hadoop-3.0.1 / hadoop-3.0.1.tjära.gzBeroende på nätverkshastigheten kan det ta upp till några minuter eftersom filen är stor i storlek:
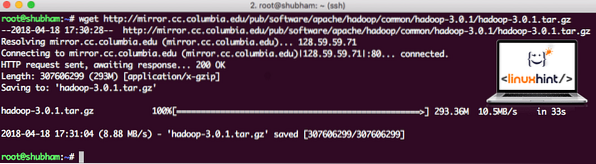
Hämtar Hadoop
Hitta de senaste Hadoop-binärfilmerna här. Nu när vi har hämtat TAR-filen kan vi extrahera i den aktuella katalogen:
tjära xvzf hadoop-3.0.1.tjära.gzDet tar några sekunder att slutföra på grund av arkivets stora filstorlek:
Hadoop arkiverades inte
Har lagt till en ny Hadoop-användargrupp
Eftersom Hadoop arbetar över HDFS kan ett nytt filsystem också störa vårt eget filsystem på Ubuntu-maskinen. För att undvika denna kollision skapar vi en helt separat användargrupp och tilldelar den till Hadoop så att den innehåller sina egna behörigheter. Vi kan lägga till en ny användargrupp med det här kommandot:
addgroup hadoopVi kommer att se något som:
Lägger till Hadoop-användargrupp
Vi är redo att lägga till en ny användare i den här gruppen:
useradd -G hadoop hadoopuserObservera att alla kommandon vi kör är själva rotanvändaren. Med aove-kommandot kunde vi lägga till en ny användare i gruppen vi skapade.
För att tillåta Hadoop-användare att utföra operationer måste vi också ge den root-åtkomst. Öppna / etc / sudoers fil med det här kommandot:
sudo visudoInnan vi lägger till något ser filen ut:
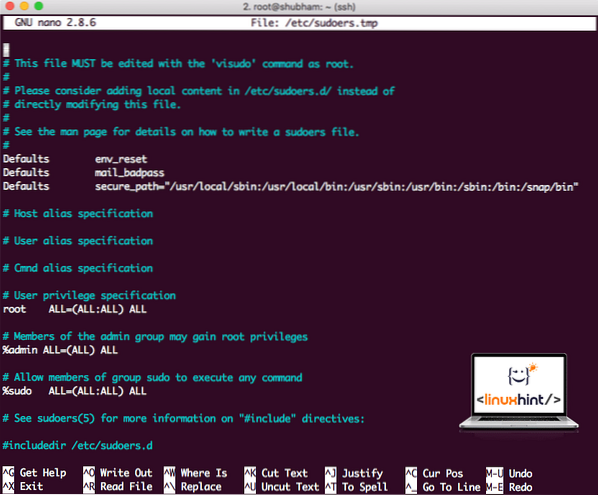
Sudoers-filen innan du lägger till något
Lägg till följande rad i slutet av filen:
hadoopuser ALL = (ALL) ALLNu kommer filen att se ut:
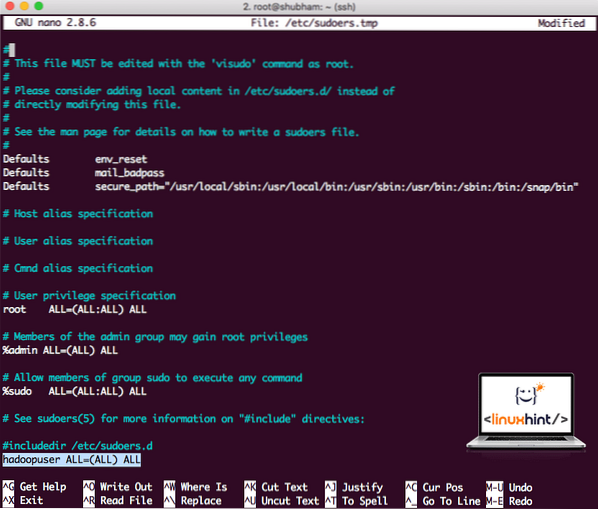
Sudoers-fil efter att ha lagt till Hadoop-användare
Detta var huvuduppsättningen för att ge Hadoop en plattform för att utföra åtgärder. Vi är redo att ställa in ett enda Hadoop-kluster nu.
Hadoop Single Node Setup: fristående läge
När det gäller den verkliga kraften hos Hadoop är den vanligtvis inställd på flera servrar så att den kan skala ovanpå en stor mängd dataset som finns i Hadoop Distribuerat filsystem (HDFS). Detta är vanligtvis bra med felsökningsmiljöer och används inte för produktionsanvändning. För att hålla processen enkel kommer vi att förklara hur vi kan göra en enda nodkonfiguration för Hadoop här.
När vi är klara med att installera Hadoop kommer vi också att köra ett exempel på Hadoop. Från och med nu heter Hadoop-filen som hadoop-3.0.1. låt oss byta namn på det till hadoop för enklare användning:
mv hadoop-3.0.1 hadoopFilen ser nu ut som:
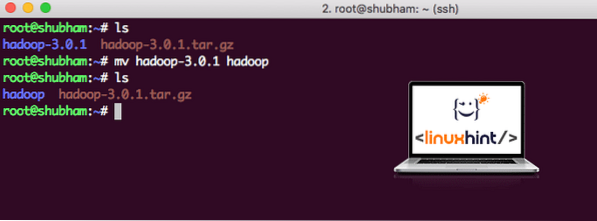
Flytta Hadoop
Dags att använda den hadoop-användare som vi skapade tidigare och tilldela ägaren av den här filen till den användaren:
chown -R hadoopuser: hadoop / root / hadoopEn bättre plats för Hadoop blir katalogen / usr / local /, så låt oss flytta den dit:
mv hadoop / usr / lokal /cd / usr / lokal /
Lägga till Hadoop till Path
För att utföra Hadoop-skript lägger vi till det i sökvägen nu. För att göra detta, öppna bashrc-filen:
vi ~ /.bashrcLägg till dessa rader i slutet av .bashrc-fil så att sökvägen kan innehålla Hadoop-körbara filsökvägen:
# Konfigurera Hadoop och Java Homeexportera HADOOP_HOME = / usr / local / hadoop
exportera JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64
exportera PATH = $ PATH: $ HADOOP_HOME / bin
Filen ser ut som:
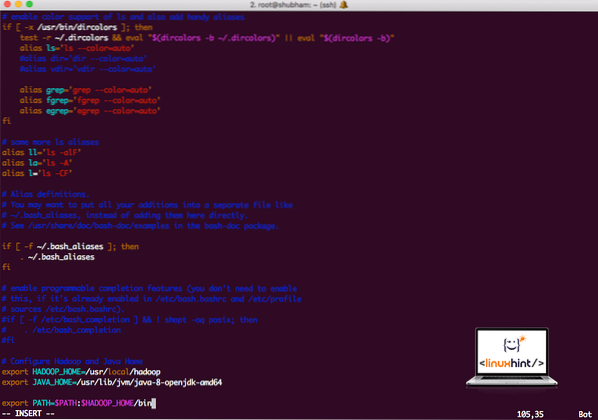
Lägga till Hadoop till Path
Eftersom Hadoop använder Java måste vi berätta för Hadoop-miljöfilen hadoop-env.sh där den ligger. Platsen för den här filen kan variera beroende på Hadoop-versioner. För att enkelt hitta var den här filen finns, kör du följande kommando direkt utanför Hadoop-katalogen:
hitta hadoop / -namn hadoop-env.shVi får utdata för filplatsen:
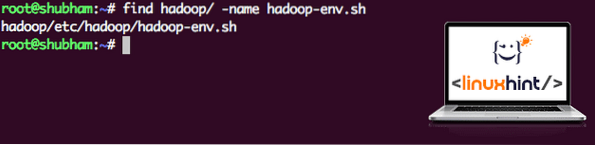
Plats för miljöfil
Låt oss redigera den här filen för att informera Hadoop om Java JDK-platsen och infoga den på den sista raden i filen och spara den:
exportera JAVA_HOME = / usr / lib / jvm / java-8-openjdk-amd64Hadoop-installationen och installationen är nu klar. Vi är redo att köra vår provansökan nu. Men vänta, vi har aldrig gjort en provansökan!
Kör provapplikation med Hadoop
Egentligen kommer Hadoop-installationen med en inbyggd exempelapplikation som är redo att köras när vi är klara med att installera Hadoop. Låter bra, eller hur?
Kör följande kommando för att köra JAR-exemplet:
hadoop burk / root / hadoop / dela / hadoop / mapreduce / hadoop-mapreduce-exempel-3.0.1.jar wordcount / root / hadoop / README.txt / root / OutputHadoop visar hur mycket bearbetning det gjorde vid noden:
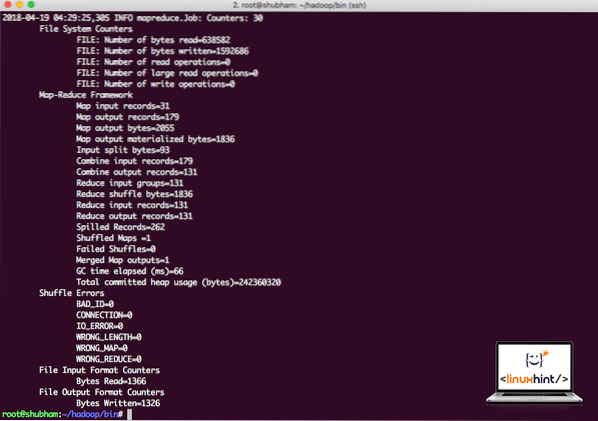
Hadoop-bearbetningsstatistik
När du har kört följande kommando ser vi filen del-r-00000 som en utgång. Gå vidare och titta på innehållet i produktionen:
katt del-r-00000Du får något som:
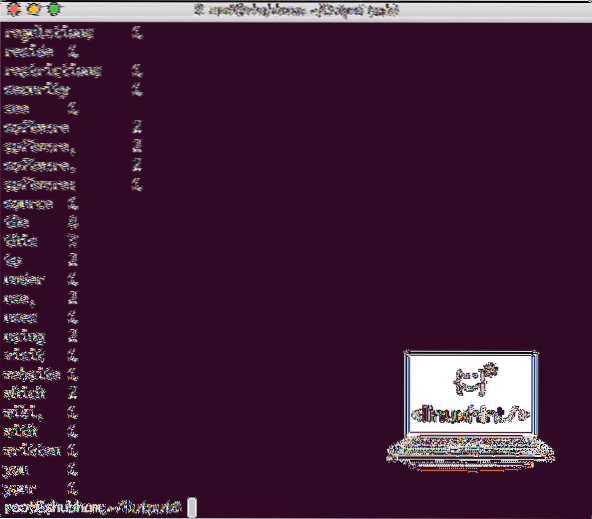
Word Count-utdata från Hadoop
Slutsats
I den här lektionen tittade vi på hur vi kan installera och börja använda Apache Hadoop på Ubuntu 17.10 maskin. Hadoop är bra för att lagra och analysera stora mängder data och jag hoppas att den här artikeln hjälper dig att komma igång med att använda den snabbt på Ubuntu.


