Apache Solr
Apache Solr är en av de mest populära NoSQL-databaserna som kan användas för att lagra data och fråga dem i realtid. Den är baserad på Apache Lucene och är skriven i Java. Precis som Elasticsearch stöder den databasfrågor via REST API: er. Det betyder att vi kan använda enkla HTTP-samtal och använda HTTP-metoder som GET, POST, PUT, DELETE etc. för att komma åt data. Det ger också ett alternativ att komma i form av XML eller JSON via REST API: er.
I den här lektionen studerar vi hur man installerar Apache Solr på Ubuntu och börjar arbeta med det genom en grundläggande uppsättning databasfrågor.
Installerar Java
För att installera Solr på Ubuntu måste vi installera Java först. Java är kanske inte installerat som standard. Vi kan verifiera det med hjälp av det här kommandot:
java -versionNär vi kör det här kommandot får vi följande utdata: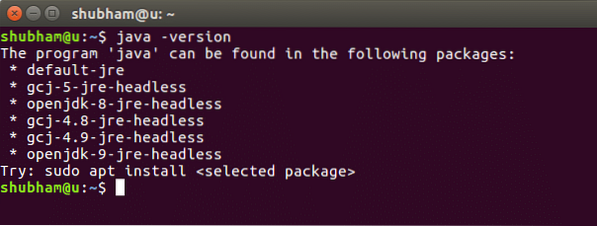
Vi installerar nu Java på vårt system. Använd det här kommandot för att göra det:
sudo add-apt-repository ppa: webupd8team / javasudo apt-get-uppdatering
sudo apt-get install oracle-java8-installer
När dessa kommandon har körts kan vi igen verifiera att Java nu är installerat med samma kommando.
Installerar Apache Solr
Vi börjar nu med att installera Apache Solr som egentligen bara handlar om några kommandon.
För att installera Solr måste vi veta att Solr inte fungerar och körs på egen hand, utan det behöver en Java Servlet-behållare för att köra, till exempel Jetty eller Tomcat Servlet-behållare. I den här lektionen kommer vi att använda Tomcat-servern men att använda Jetty är ganska lika.
Det som är bra med Ubuntu är att det tillhandahåller tre paket med vilka Solr enkelt kan installeras och startas. Dom är:
- solr-common
- solr-tomcat
- solr-brygga
Det är självbeskrivande att solr-common behövs för båda behållarna medan solr-jetty behövs för Jetty och solr-tomcat behövs endast för Tomcat-servern. Eftersom vi redan har installerat Java kan vi ladda ner Solr-paketet med det här kommandot:
sudo wget http: // www-eu.apache.org / dist / lucene / solr / 7.2.1 / solr-7.2.1.blixtlåsEftersom det här paketet innehåller många paket inklusive Tomcat-servern, kan det ta några minuter att ladda ner och installera allt. Hämta den senaste versionen av Solr-filer härifrån.
När installationen är klar kan vi packa upp filen med följande kommando:
packa upp -q solr-7.2.1.blixtlåsÄndra nu din katalog till zip-filen så visas följande filer inuti:
Startar Apache Solr Node
Nu när vi har laddat ner Apache Solr-paket på vår maskin kan vi göra mer som utvecklare från ett nodgränssnitt, så vi startar en nodinstans för Solr där vi faktiskt kan samla in, lagra data och göra sökbara frågor.
Kör följande kommando för att starta klusterinstallationen:
./ bin / solr start -e molnVi ser följande utdata med det här kommandot: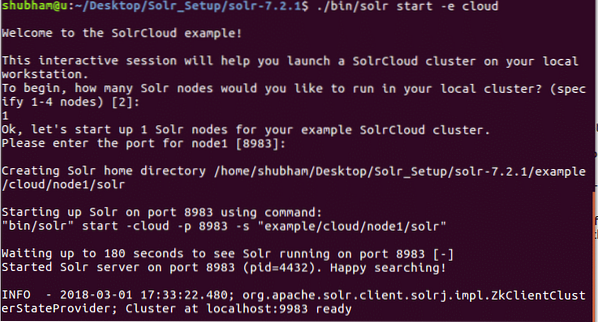
Många frågor kommer att ställas, men vi kommer att ställa in ett enda Solr-kluster med alla standardkonfigurationer. Som visas i det sista steget kommer Solr-nodgränssnittet att finnas tillgängligt på:
där 8983 är standardporten för noden. När vi väl har besökt ovanstående URL kommer vi att se nodgränssnittet: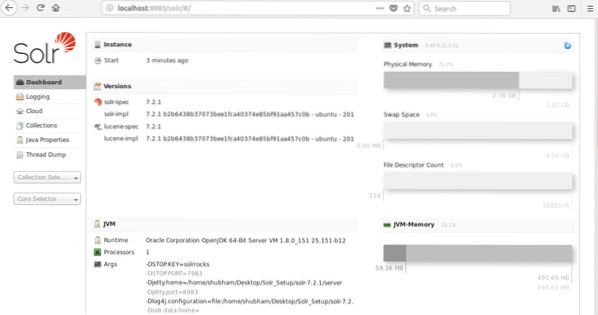
Använda samlingar i Solr
Nu när vårt nodgränssnitt är igång kan vi skapa en samling med kommandot:
./ bin / solr create_collection -c linux_hint_collectionoch vi kommer att se följande utdata:
Undvik varningarna för nu. Vi kan även se samlingen i nodgränssnittet också nu:
Nu kan vi börja med att definiera ett schema i Apache Solr genom att välja schemasektionen: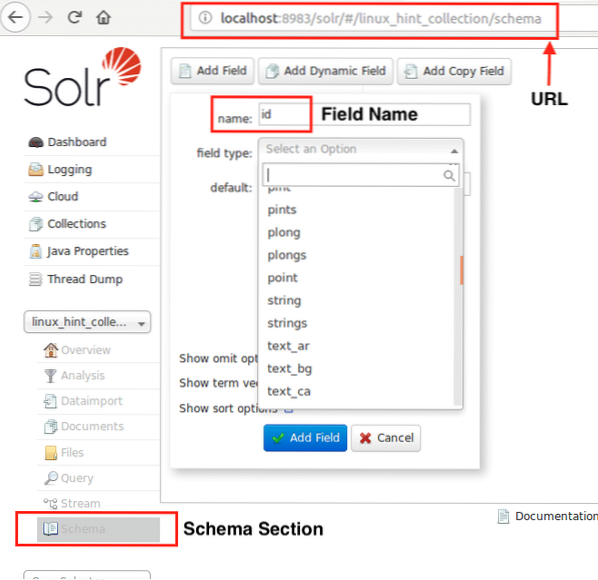
Vi kan nu börja infoga data i våra samlingar. Låt oss infoga ett JSON-dokument i vår samling här:
curl -X POST -H 'Content-Type: application / json''http: // localhost: 8983 / solr / linux_hint_collection / update / json / docs' --data-binary '
"id": "iduye",
"name": "Shubham"
'
Vi kommer att se ett framgångssvar mot detta kommando:
Som ett sista kommando, låt oss se hur vi kan Hämta all data från Solr-samlingen:
Vi ser följande utdata:


