Installerar Tesseract OCR i Linux
Tesseract OCR är tillgängligt som standard på de flesta Linux-distributioner. Du kan installera den i Ubuntu med kommandot nedan:
$ sudo apt installera tesseract-ocrDetaljerade instruktioner för andra distributioner finns tillgängliga här. Även om Tesseract OCR är tillgängligt i förvar för många Linux-distributioner som standard rekommenderas det att installera den senaste versionen från länken som nämns ovan för förbättrad noggrannhet och analysering.
Installera stöd för ytterligare språk i Tesseract OCR
Tesseract OCR innehåller stöd för att upptäcka text på över 100 språk. Men du får bara stöd för att upptäcka text på engelska med standardinstallationen i Ubuntu. För att lägga till stöd för att analysera ytterligare språk i Ubuntu, kör ett kommando i följande format:
$ sudo apt installera tesseract-ocr-hinKommandot ovan kommer att lägga till stöd för hindi-språket till Tesseract OCR. Ibland kan du få bättre noggrannhet och resultat genom att installera stöd för språkmanus. Till exempel, installation och användning av tesseract-paketet för Devanagari-skript "tesseract-ocr-script-deva" gav mig mycket mer exakta resultat än att använda paketet "tesseract-ocr-hin".
I Ubuntu kan du hitta rätt paketnamn för alla språk och skript genom att köra kommandot nedan:
$ apt-cache sök tesseract-När du har identifierat rätt paketnamn som ska installeras ersätter du strängen "tesseract-ocr-hin" med den i det första kommandot som anges ovan.
Använda Tesseract OCR för att extrahera text från bilder
Låt oss ta ett exempel på en bild som visas nedan (hämtad från Wikipedia-sidan för Linux):

För att extrahera text från bilden ovan måste du köra ett kommando i följande format:
$ tesseract-fångst.png-utgång -l engAtt köra kommandot ovan ger följande utdata:
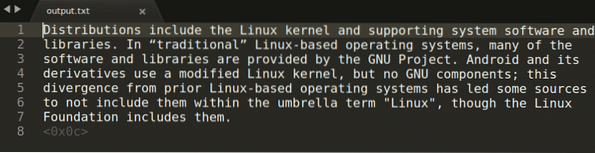
I kommandot ovan, “fånga.png ”avser bilden från vilken du vill extrahera texten. Den fångade utgången lagras sedan i “utgången.txt ”-fil. Du kan ändra språk genom att ersätta argumentet “eng” med ditt eget val. För att se alla giltiga språk, kör kommandot nedan:
$ tesseract --list-langsDet visar förkortningskoder för alla språk som stöds av Tesseract OCR på ditt system. Som standard visar den bara “eng” som utdata. Men om du installerar paket för ytterligare språk som förklaras ovan kommer detta kommando att lista fler språk som du kan använda för att upptäcka text (som ISO 639 språkkoder med 3 bokstäver).
Om bilden innehåller text på flera språk, definiera primärspråket först följt av ytterligare språk åtskilda av plustecken.
$ tesseract-fångst.png-utdata -l eng + fraOm du vill lagra utdata som en sökbar PDF-fil, kör ett kommando i följande format:
$ tesseract-fångst.png-utdata -l sv pdfObservera att den sökbara PDF-filen inte innehåller någon redigerbar text. Den inkluderar originalbilden, med ett ytterligare lager som innehåller den igenkända texten ovanpå bilden. Så även om du kommer att kunna söka korrekt i PDF-filen med vilken PDF-läsare som helst, kommer du inte att kunna redigera texten.
En annan punkt du bör notera att noggrannheten för textdetektering ökar kraftigt om bildfilen är av hög kvalitet. Valet, använd alltid förlustfria filformat eller PNG-filer. Att använda JPG-filer ger kanske inte de bästa resultaten.
Extrahera text från en flersidig PDF-fil
Tesseract OCR stöder inte extrahering av text från PDF-filer. Det är dock möjligt att extrahera text från en flersidig PDF-fil genom att konvertera varje sida till en bildfil. Kör kommandot nedan för att konvertera en PDF-fil till en uppsättning bilder:
$ pdftoppm -png-fil.pdf-utdataFör varje sida i PDF-filen får du motsvarande “output-1.png ”,“ output-2.png ”-fil och så vidare.
För att extrahera text från dessa bilder med ett enda kommando måste du använda en "for loop" i ett bash-kommando:
$ för jag i *.png; gör tesseract "$ i" "output- $ i" -l eng; Gjort;Att köra ovanstående kommando extraherar text från alla “.png-filer som finns i arbetskatalogen och lagrar den igenkända texten i “output-original_filename.txt-filer. Du kan ändra den mellersta delen av kommandot enligt dina behov.
Om du vill kombinera alla textfiler som innehåller den igenkända texten, kör kommandot nedan:
$ katt *.txt> gick med.TextProcessen för att extrahera text från en flersidig PDF-fil till sökbara PDF-filer är nästan densamma. Du måste ange ett extra "pdf" -argument till kommandot:
$ för jag i *.png; gör tesseract "$ i" "output- $ i" -l eng pdf; Gjort;Om du vill kombinera alla sökbara PDF-filer som innehåller den igenkända texten, kör du kommandot nedan:
$ pdfunite *.pdf gick med.pdfBåde "pdftoppm" och "pdfunite" installeras som standard på den senaste stabila versionen av Ubuntu.
Fördelar och nackdelar med att extrahera text i TXT och sökbara PDF-filer
Om du extraherar igenkänd text till TXT-filer får du redigerbar textutmatning. Dokumentformatering kommer dock att gå förlorad (fetstil, kursiva tecken och så vidare). Sökbara PDF-filer behåller originalformateringen, men du kommer att förlora textredigeringsfunktionerna (du kan fortfarande kopiera råtext). Om du öppnar den sökbara PDF-filen i någon PDF-redigerare får du inbäddade bilder i filen och inte råtextutmatning. Omvandling av sökbara PDF-filer till HTML eller EPUB ger dig också inbäddade bilder.
Slutsats
Tesseract OCR är en av de mest använda OCR-motorerna idag. Det är en gratis öppen källkod och stöder över hundra språk. När du använder Tesseract OCR, se till att använda bilder med hög upplösning och rätta språkkoder i kommandoradsargument för att förbättra noggrannheten för textdetektering.


