Detta är en uppföljningsartikel till de två föregående [2,3]. Hittills laddade vi indexerad data i Apache Solr-lagringen och frågade data om det. Nu lär du dig hur du ansluter relationsdatabashanteringssystemet PostgreSQL [4] till Apache Solr och gör en sökning i det med hjälp av Solr. Detta gör det nödvändigt att göra flera steg som beskrivs nedan mer detaljerat - ställa in PostgreSQL, förbereda en datastruktur i en PostgreSQL-databas och ansluta PostgreSQL till Apache Solr och göra vår sökning.
Steg 1: Konfigurera PostgreSQL
Om PostgreSQL - en kort info
PostgreSQL är ett genialt objektrelationellt databashanteringssystem. Den har funnits tillgänglig och har genomgått en aktiv utveckling i över 30 år nu. Den härstammar från University of California, där den ses som Ingres efterträdare [7].
Från början är den tillgänglig under öppen källkod (GPL), gratis att använda, modifiera och distribuera. Det används ofta och är mycket populärt i branschen. PostgreSQL designades ursprungligen endast för att köras på UNIX / Linux-system och senare för att köras på andra system som Microsoft Windows, Solaris och BSD. Den nuvarande utvecklingen av PostgreSQL görs över hela världen av många volontärer.
PostgreSQL-installation
Om det inte är gjort ännu, installera PostgreSQL-servern och klienten lokalt, till exempel på Debian GNU / Linux som beskrivs nedan med hjälp av apt. Två artiklar handlar om PostgreSQL - Yunis Saids artikel [5] diskuterar installationen på Ubuntu. Ändå kliar han bara ytan medan min tidigare artikel fokuserar på kombinationen av PostgreSQL med GIS-tillägget PostGIS [6]. Beskrivningen här sammanfattar alla steg vi behöver för just denna inställning.
# apt installera postgresql-13 postgresql-client-13Kontrollera sedan att PostgreSQL körs med hjälp av kommandot pg_isready. Detta är ett verktyg som ingår i PostgreSQL-paketet.
# pg_isready/ var / run / postgresql: 5432 - Anslutningar accepteras
Utdata ovan visar att PostgreSQL är redo och väntar på inkommande anslutningar på port 5432. Om inget annat anges är detta standardkonfigurationen. Nästa steg är att ställa in lösenordet för UNIX-användaren Postgres:
# passwd PostgresTänk på att PostgreSQL har en egen användardatabas, medan den administrativa PostgreSQL-användaren Postgres ännu inte har ett lösenord. Det föregående steget måste också göras för PostgreSQL-användaren Postgres:
# su - Postgres$ psql -c "ALTER USER Postgres WITH LÖSENORD" lösenord ";"
För enkelhetens skull är det valda lösenordet bara ett lösenord och bör ersättas med en säkrare lösenordsfras på andra system än testning. Kommandot ovan kommer att ändra den interna användartabellen för PostgreSQL. Var medveten om de olika citattecken - lösenordet i enstaka citattecken och SQL-frågan i dubbla citattecken för att förhindra att skaltolken utvärderar kommandot på fel sätt. Lägg också till ett semikolon efter SQL-frågan före dubbla citat i slutet av kommandot.
Därefter ansluter du av administrativa skäl till PostgreSQL som användar-Postgres med det tidigare skapade lösenordet. Kommandot heter psql:
$ psqlAnslutning från Apache Solr till PostgreSQL-databasen görs som användarsolr. Så låt oss lägga till PostgreSQL-användaren solr och ställa in ett motsvarande lösenord för honom på en gång:
$ CREATE USER solr WITH PASSWD 'solr';För enkelhetens skull är det valda lösenordet bara solr och bör ersättas med en säkrare lösenordsfras på system som är i produktion.
Steg 2: Förbereda en datastruktur
För att lagra och hämta data krävs en motsvarande databas. Kommandot nedan skapar en databas över bilar som tillhör användarens solr och kommer att användas senare.
$ CREATE DATABASE bilar MED ÄGARE = solr;Anslut sedan till de nyskapade databasbilarna som användarsolr. Alternativet -d (kort alternativ för -dbname) definierar databasnamnet och -U (kort alternativ för -användarnamn) namnet på PostgreSQL-användaren.
$ psql -d bilar -U solrEn tom databas är inte användbar, men strukturerade tabeller med innehåll gör det. Skapa strukturen för bordsvagnarna enligt följande:
$ CREATE TABLE bilar (id int,
gör varchar (100),
modell varchar (100),
beskrivning varchar (100),
färgvarchar (50),
pris int
);
Tabellbilarna innehåller sex datafält - id (heltal), fabrikat (en längd 100), modell (längd 100), beskrivning (längd 100), färg (längd 50) och pris (heltal). För att få några exempeldata lägg till följande värden i tabellbilarna som SQL-uttalanden:
$ INSERT INTO bilar (id, märke, modell, beskrivning, färg, pris)VÄRDEN (1, 'BMW', 'X5', 'Cool bil', 'grå', 45000);
$ INSERT INTO bilar (id, märke, modell, beskrivning, färg, pris)
VÄRDEN (2, 'Audi', 'Quattro', 'racerbil', 'vit', 30000);
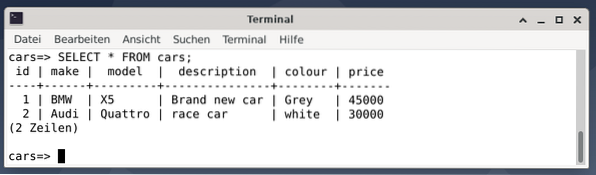
Resultatet är två poster som representerar en grå BMW X5 som kostar 45000 USD, beskriven som en cool bil, och en vit racerbil Audi Quattro som kostar 30000 USD.
Gå sedan ut från PostgreSQL-konsolen med \ q eller avsluta.
$ \ qSteg 3: Ansluta PostgreSQL med Apache Solr
PostgreSQL och Apache Solrs anslutning är baserad på två programvaror - en Java-drivrutin för PostgreSQL som heter Java Database Connectivity (JDBC) -drivrutin och en förlängning av Solr-serverkonfigurationen. JDBC-drivrutinen lägger till ett Java-gränssnitt till PostgreSQL, och den ytterligare posten i Solr-konfigurationen berättar för Solr hur man ansluter till PostgreSQL med JDBC-drivrutinen.
Lägga till JDBC-drivrutinen görs som användarrot enligt följande och installerar JDBC-drivrutinen från Debians paketförvar:
# apt-get install libpostgresql-jdbc-javaPå Apache Solr-sidan måste en motsvarande nod också finnas. Om inte gjort ännu, som UNIX-användare solr, skapa nodbilarna enligt följande:
$ bin / solr skapa -c bilarUtöka sedan Solr-konfigurationen för den nyskapade noden. Lägg till raderna nedan till filen / var / solr / data / cars / conf / solrconfig.xml:
db-data-config.xmlSkapa dessutom en fil / var / solr / data / bilar / conf / data-config.och lagra följande innehåll i den:
Raderna ovan motsvarar de tidigare inställningarna och definierar JDBC-drivrutinen, ange porten 5432 för att ansluta till PostgreSQL DBMS som användaren solr med motsvarande lösenord och ställ in SQL-frågan som ska köras från PostgreSQL. För enkelhetens skull är det ett SELECT-uttalande som tar hela innehållet i tabellen.
Starta sedan om Solr-servern för att aktivera dina ändringar. Som användarrot kör följande kommando:
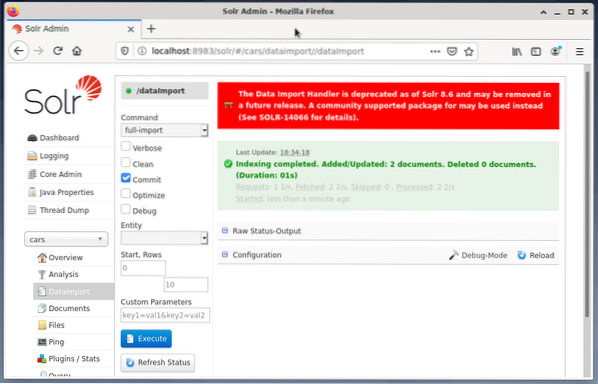
# systemctl starta om solrDet sista steget är importen av data, till exempel med hjälp av Solr webbgränssnitt. Rutan för val av nod väljer nodbilar, sedan från nodmenyn under posten Dataimport följt av valet av fullimport från kommandomenyn direkt till den. Slutligen trycker du på knappen Kör. Figuren nedan visar att Solr framgångsrikt har indexerat data.
Steg 4: Fråga efter data från DBMS
Föregående artikel [3] handlar om att fråga data i detalj, hämta resultatet och välja önskat utdataformat - CSV, XML eller JSON. Frågan på data görs på samma sätt som du har lärt dig tidigare och ingen skillnad syns för användaren. Solr gör allt arbete bakom kulisserna och kommunicerar med PostgreSQL DBMS ansluten enligt definition i vald Solr-kärna eller kluster.
Användningen av Solr ändras inte och frågor kan skickas via Solr-administratörsgränssnittet eller med curl eller wget på kommandoraden. Du skickar en Get-begäran med en specifik URL till Solr-servern (fråga, uppdatera eller ta bort). Solr bearbetar begäran med DBMS som en lagringsenhet och returnerar resultatet av begäran. Därefter efterbearbetar du svaret lokalt.
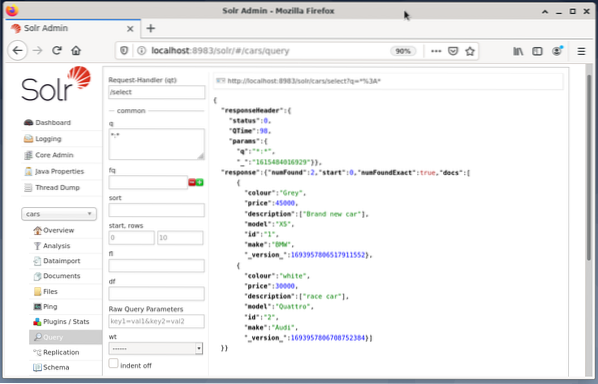
Exemplet nedan visar resultatet av frågan “/ select?q = *. * ”I JSON-format i Solr-administratörsgränssnittet. Data hämtas från databasbilarna som vi skapade tidigare.
Slutsats
Den här artikeln visar hur du frågar efter en PostgreSQL-databas från Apache Solr och förklarar motsvarande installation. I nästa del av denna serie lär du dig att kombinera flera Solr-noder i ett Solr-kluster.
Om Författarna
Jacqui Kabeta är miljöaktivist, ivrig forskare, tränare och mentor. I flera afrikanska länder har hon arbetat inom IT-industrin och NGO-miljöer.
Frank Hofmann är IT-utvecklare, tränare och författare och föredrar att arbeta från Berlin, Genève och Kapstaden. Medförfattare till Debian Package Management Book tillgänglig från dpmb.org
Länkar och referenser
- [1] Apache Solr, https: // lucene.apache.org / solr /
- [2] Frank Hofmann och Jacqui Kabeta: Introduktion till Apache Solr. Del 1, https: // linuxhint.com / apache-solr-setup-a-node /
- [3] Frank Hofmann och Jacqui Kabeta: Introduktion till Apache Solr. Fråga om data. Del 2, http: // linuxhint.com
- [4] PostgreSQL, https: // www.postgresql.org /
- [5] Younis Said: Hur man installerar och konfigurerar PostgreSQL-databas på Ubuntu 20.04, https: // linuxhint.com / install_postgresql_-ubuntu /
- [6] Frank Hofmann: Konfigurera PostgreSQL med PostGIS på Debian GNU / Linux 10, https: // linuxhint.com / setup_postgis_debian_postgres /
- [7] Ingres, Wikipedia, https: // sv.wikipedia.org / wiki / Ingres_ (databas)


