Den här artikeln visar hur du ställer in Selenium på din Linux-distribution (i.e., Ubuntu), samt hur man utför grundläggande webbautomation och skrotning med Selenium Python 3-biblioteket.
Förutsättningar
För att testa kommandona och exemplen som används i den här artikeln måste du ha följande:
1) En Linux-distribution (helst Ubuntu) installerad på din dator.
2) Python 3 installerad på din dator.
3) PIP 3 installerad på din dator.
4) Webbläsaren Google Chrome eller Firefox installerad på din dator.
Du kan hitta många artiklar om dessa ämnen på LinuxHint.com. Var noga med att kolla in dessa artiklar om du behöver ytterligare hjälp.
Förbereder Python 3 Virtual Environment för projektet
Python Virtual Environment används för att skapa en isolerad Python-projektkatalog. Python-modulerna som du installerar med PIP installeras endast i projektkatalogen snarare än globalt.
Python virtualenv modulen används för att hantera virtuella Python-miljöer.
Du kan installera Python virtualenv modul globalt med PIP 3 enligt följande:
$ sudo pip3 installera virtualenv
PIP3 laddar ner och installerar alla nödvändiga moduler globalt.

Vid denna punkt, Python virtualenv modulen ska installeras globalt.
Skapa projektkatalogen python-selen-basisk / i din nuvarande arbetskatalog, enligt följande:
$ mkdir -pv python-selen-basic / drivrutiner
Navigera till din nyskapade projektkatalog python-selen-basisk /, som följer:
$ cd python-selen-basic /
Skapa en virtuell Python-miljö i din projektkatalog med följande kommando:
$ virtualenv .env
Den virtuella Python-miljön ska nu skapas i din projektkatalog.''

Aktivera den virtuella Python-miljön i din projektkatalog via följande kommando:
$ källa .env / bin / aktivera
Som du kan se är den virtuella Python-miljön aktiverad för denna projektkatalog.

Installerar Selenium Python Library
Selenium Python-biblioteket finns tillgängligt i det officiella Python PyPI-förvaret.
Du kan installera detta bibliotek med PIP 3 enligt följande:
$ pip3 installera selen
Selenium Python-biblioteket ska nu installeras.
Nu när Selenium Python-biblioteket är installerat är nästa sak du behöver göra att installera en webbdrivrutin för din favoritwebbläsare. I den här artikeln visar jag dig hur du installerar Firefox- och Chrome-webbdrivrutinerna för Selenium.
Installerar Firefox Gecko-drivrutin
Med Firefox Gecko-drivrutin kan du styra eller automatisera Firefox-webbläsaren med Selenium.
För att ladda ner Firefox Gecko Driver, besök GitHub-utgivningssidan för mozilla / geckodriver från en webbläsare.
Som du kan se, v0.26.0 är den senaste versionen av Firefox Gecko Driver när den här artikeln skrevs.
För att ladda ner Firefox Gecko Driver, bläddra neråt lite och klicka på Linux geckodriver tar.gz-arkiv, beroende på operativsystemets arkitektur.
Om du använder ett 32-bitars operativsystem, klicka på geckodriver-v0.26.0-linux32.tjära.gz länk.
Om du använder ett 64-bitars operativsystem, klicka på geckodriver-v0.26.0-linuxx64.tjära.gz länk.
I mitt fall laddar jag ner 64-bitarsversionen av Firefox Gecko Driver.
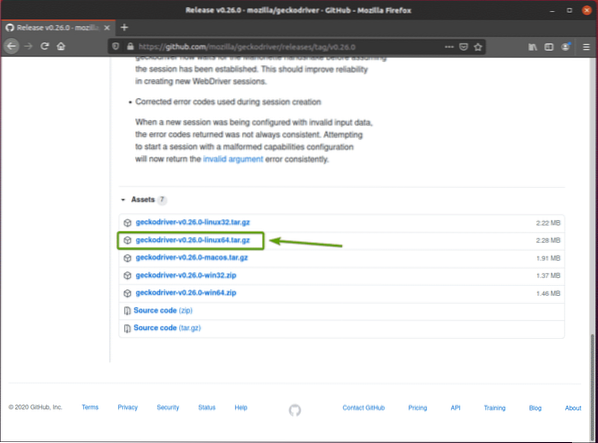
Din webbläsare bör uppmana dig att spara arkivet. Välj Spara fil och klicka sedan på OK.
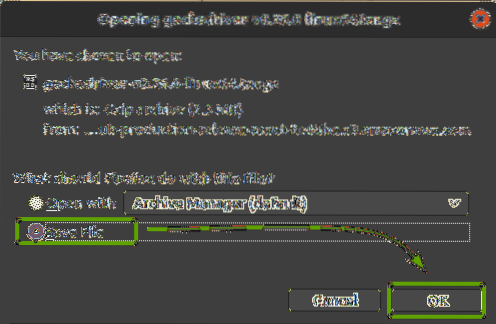
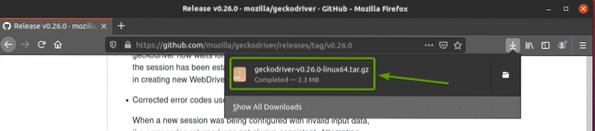
Firefox Gecko-drivrutinsarkivet bör laddas ner i ~ / Nedladdningar katalog.
Extrahera geckodriver-v0.26.0-linux64.tjära.gz arkiv från ~ / Nedladdningar katalog till förare / katalog för ditt projekt genom att ange följande kommando:
$ tar -xzf ~ / Nedladdningar / geckodriver-v0.26.0-linux64.tjära.gz -C drivrutiner /
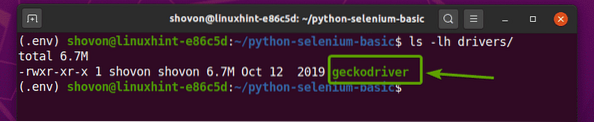
När Firefox Gecko Driver-arkiv har extraherats, en ny geckodriver binär fil ska skapas i förare / katalog över ditt projekt, som du kan se på skärmdumpen nedan.
Testar Selenium Firefox Gecko Driver
I det här avsnittet visar jag dig hur du ställer in ditt allra första Selenium Python-skript för att testa om Firefox Gecko Driver fungerar.
Öppna först projektkatalogen python-selen-basisk / med din favorit IDE eller redaktör. I den här artikeln kommer jag att använda Visual Studio Code.
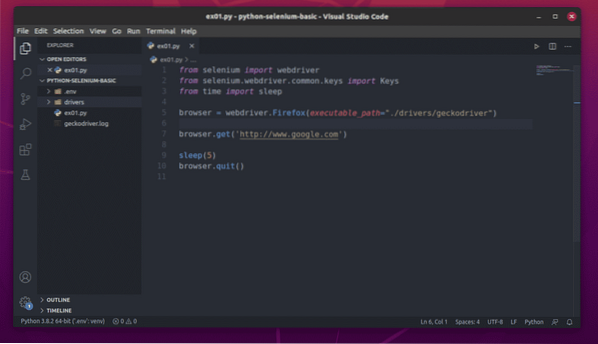
Skapa det nya Python-skriptet ex01.py, och skriv följande rader i skriptet.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
från tid importera sömn
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.få ('http: // www.Google.com ')
sova (5)
webbläsare.sluta()
När du är klar sparar du ex01.py Python-skript.
Jag kommer att förklara koden i ett senare avsnitt av den här artikeln.
Följande rad konfigurerar Selenium för att använda Firefox Gecko Driver från förare / katalog över ditt projekt.

För att testa om Firefox Gecko-drivrutinen fungerar med Selen, kör du följande ex01.py Python-skript:
$ python3 ex01.py
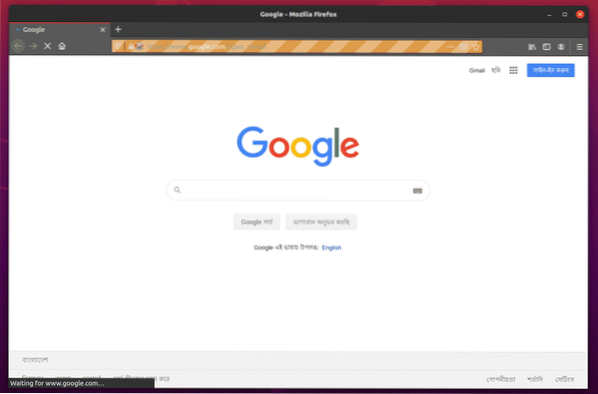
Firefox-webbläsaren ska automatiskt besöka Google.com och stäng sig efter 5 sekunder. Om detta inträffar fungerar Selenium Firefox Gecko Driver korrekt.
Installerar Chrome Web Driver
Med Chrome Web Driver kan du styra eller automatisera webbläsaren Google Chrome med Selenium.
Du måste ladda ner samma version av Chrome Web Driver som din Google Chrome-webbläsare.
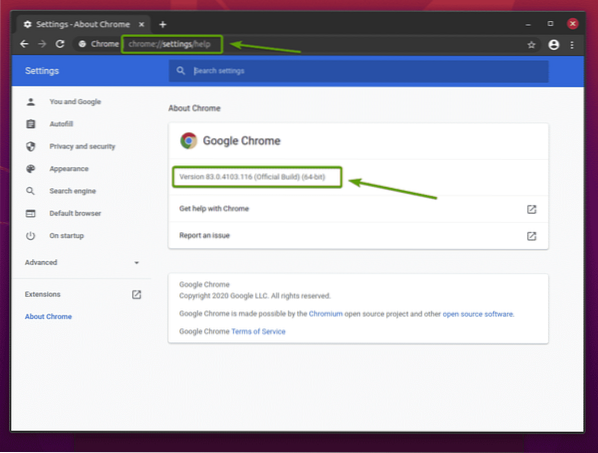
För att hitta versionsnumret för din Google Chrome-webbläsare, besök chrome: // settings / help i Google Chrome. Versionsnumret ska finnas i Om Chrome avsnitt, som du kan se på skärmdumpen nedan.
I mitt fall är versionsnumret 83.0.4103.116. De tre första delarna av versionsnumret (83.0.4103, i mitt fall) måste matcha de tre första delarna av Chrome Web Driver-versionsnumret.
För att ladda ner Chrome Web Driver, besök den officiella nedladdningssidan för Chrome.
I Aktuella släpp avsnittet, Chrome Web Driver för de senaste versionerna av webbläsaren Google Chrome kommer att finnas tillgängligt, som du kan se på skärmdumpen nedan.
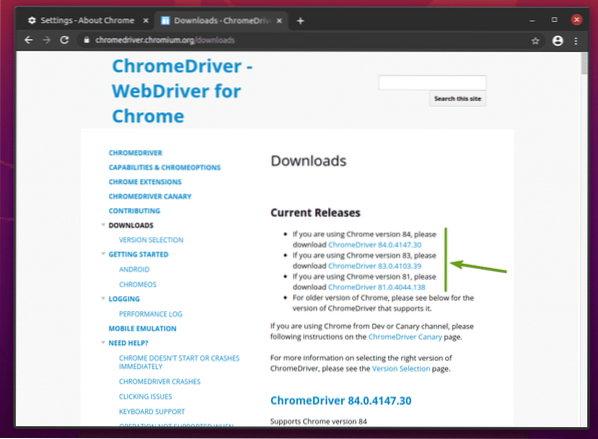
Om versionen av Google Chrome du använder inte finns i Aktuella släpp avsnittet, bläddra lite neråt och du borde hitta önskad version.
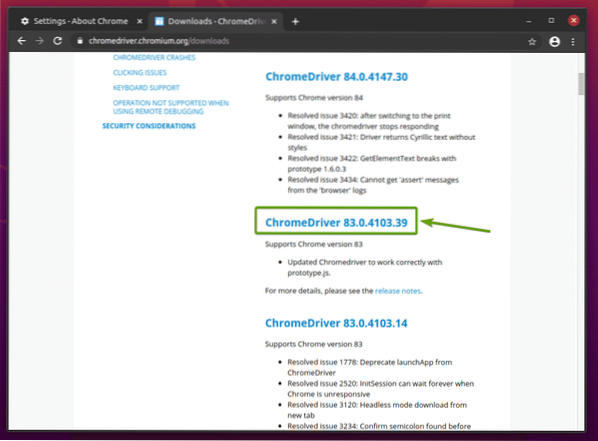
När du klickar på rätt version av Chrome Web Driver, bör det ta dig till nästa sida. Klicka på chromedriver_linux64.blixtlås länk, som noterad i skärmdumpen nedan.
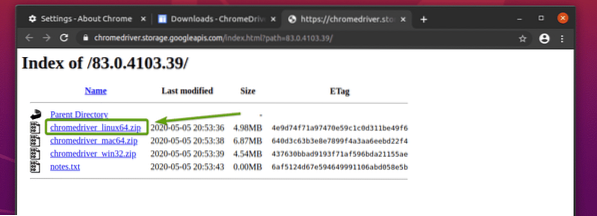
Chrome Web Driver-arkivet ska nu laddas ner.
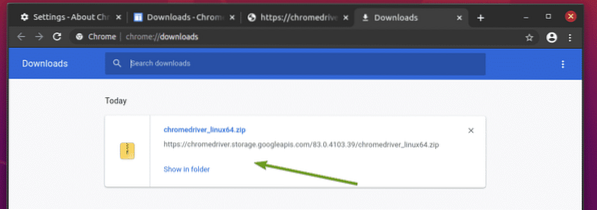
Chrome Web Driver-arkivet ska nu laddas ner i ~ / Nedladdningar katalog.
Du kan extrahera chromedriver-linux64.blixtlås arkiv från ~ / Nedladdningar katalog till förare / katalog över ditt projekt med följande kommando:
$ unzip ~ / Nedladdningar / chromedriver_linux64.zip -d drivrutiner /
När Chrome Web Driver-arkivet har extraherats, en ny kromförare binär fil ska skapas i förare / katalog över ditt projekt, som du kan se på skärmdumpen nedan.
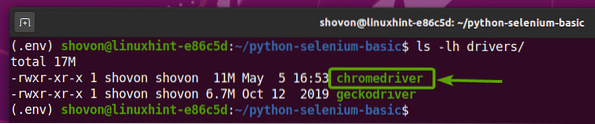
Testar Selenium Chrome Web Driver
I det här avsnittet kommer jag att visa dig hur du ställer in ditt allra första Selenium Python-skript för att testa om Chrome Web Driver fungerar.
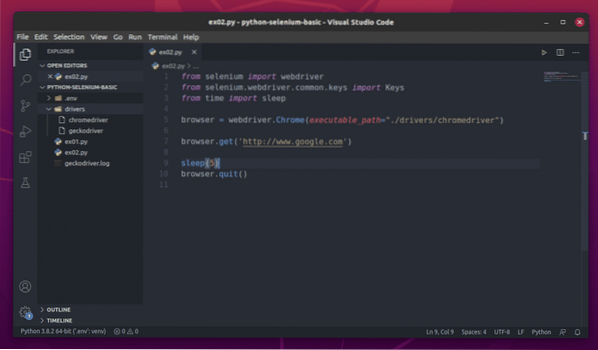
Skapa först det nya Python-skriptet ex02.py, och skriv följande koderader i skriptet.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
från tid importera sömn
webbläsare = webdriver.Chrome (executable_path = "./ drivers / chromedriver ")
webbläsare.få ('http: // www.Google.com ')
sova (5)
webbläsare.sluta()
När du är klar sparar du ex02.py Python-skript.
Jag kommer att förklara koden i ett senare avsnitt av den här artikeln.
Följande rad konfigurerar Selen att använda Chrome Web Driver från förare / katalog över ditt projekt.

För att testa om Chrome Web Driver arbetar med Selen, kör du ex02.py Python-skript, enligt följande:
$ python3 ex01.py
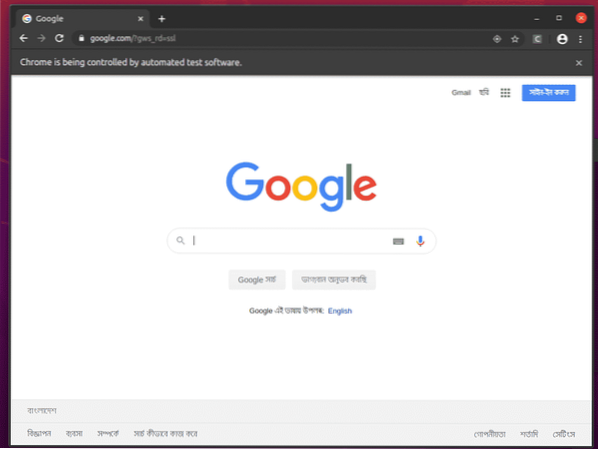
Webbläsaren Google Chrome ska automatiskt besöka Google.com och stänga sig själv efter 5 sekunder. Om detta inträffar fungerar Selenium Firefox Gecko Driver korrekt.
Grunderna för webbskrapning med selen
Jag kommer att använda Firefox-webbläsaren från och med nu. Du kan också använda Chrome om du vill.
Ett grundläggande Selenium Python-skript ska se ut som manuset som visas på skärmdumpen nedan.
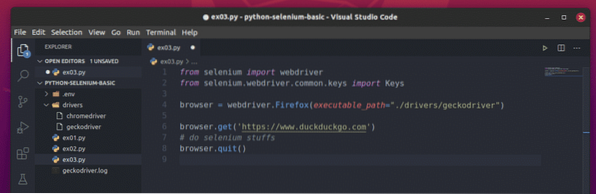
Importera först selen webbdrivare från selen modul.

Importera sedan Nycklar från selen.webbdrivare.allmänning.knapparna. Detta hjälper dig att skicka tangenttryckningar till den webbläsare du automatiserar från Selenium.

Följande rad skapar en webbläsare objekt för Firefox-webbläsaren med hjälp av Firefox Gecko Driver (Webdriver). Du kan styra Firefox-webbläsaråtgärder med detta objekt.

För att ladda en webbplats eller URL (jag laddar webbplatsen https: // www.duckduckgo.com), ring skaffa sig() metod för webbläsare objekt i din Firefox-webbläsare.

Med Selen kan du skriva dina tester, utföra webbskrotning och slutligen stänga webbläsaren med sluta() metod för webbläsare objekt.

Ovan är den grundläggande layouten för ett Selenium Python-skript. Du kommer att skriva dessa rader i alla dina Selen Python-skript.
Exempel 1: Skriva ut titeln på en webbsida
Detta kommer att vara det enklaste exemplet som diskuteras med Selen. I det här exemplet kommer vi att skriva ut titeln på webbsidan vi kommer att besöka.
Skapa den nya filen ex04.py och skriv följande rader med koder i den.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.få ('https: // www.duckduckgo.com ')
skriv ut ("Titel:% s"% webbläsare.titel)
webbläsare.sluta()
När du är klar sparar du filen.
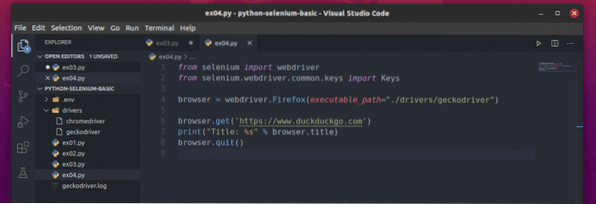
Här, den webbläsare.titel används för att komma åt titeln på den besökta webbsidan och skriva ut() funktionen kommer att användas för att skriva ut titeln i konsolen.

Efter att ha kört ex04.py skript bör det:
1) Öppna Firefox
2) Ladda din önskade webbsida
3) Hämta sidans titel
4) Skriv ut titeln på konsolen
5) Och slutligen stäng webbläsaren
Som du kan se ex04.py skriptet har skrivit ut webbsidans titel snyggt i konsolen.
$ python3 ex04.py
Exempel 2: Skriva ut titlar på flera webbsidor
Som i föregående exempel kan du använda samma metod för att skriva ut titeln på flera webbsidor med Python-slingan.
Skapa det nya Python-skriptet för att förstå hur detta fungerar ex05.py och skriv följande kodrader i skriptet:
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
urls = ['https: // www.duckduckgo.com ',' https: // linuxhint.com ',' https: // yahoo.com ']
för webbadress i webbadresser:
webbläsare.få (url)
skriv ut ("Titel:% s"% webbläsare.titel)
webbläsare.sluta()
När du är klar sparar du Python-skriptet ex05.py.
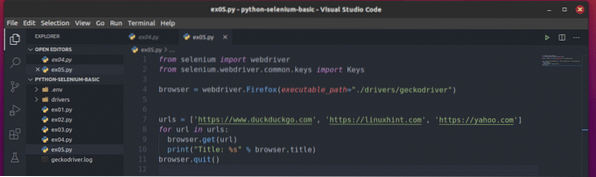
Här, den webbadresser listan behåller webbadressen till varje webbsida.

A för loop används för att iterera genom webbadresser lista objekt.
Vid varje iteration ber Selenium webbläsaren att besöka url och få titeln på webbsidan. När Selenium har extraherat webbsidans titel skrivs den ut i konsolen.

Kör Python-skriptet ex05.py, och du bör se titeln på varje webbsida i webbadresser lista.
$ python3 ex05.py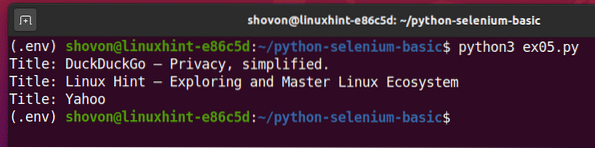
Detta är ett exempel på hur Selen kan utföra samma uppgift med flera webbsidor eller webbplatser.
Exempel 3: Extrahera data från en webbsida
I det här exemplet visar jag dig grunderna för att extrahera data från webbsidor med Selen. Detta kallas också webbskrapning.
Besök först Random.org-länk från Firefox. Sidan ska generera en slumpmässig sträng, som du kan se på skärmdumpen nedan.
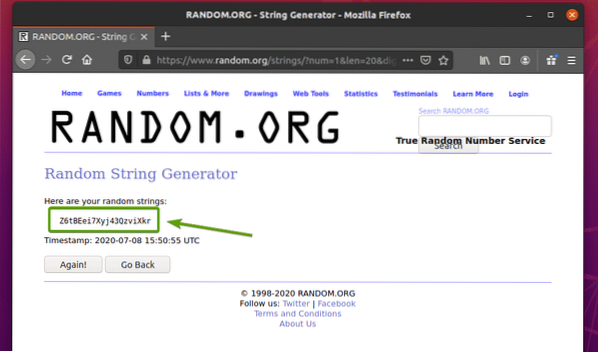
För att extrahera slumpmässiga strängdata med Selen, måste du också känna till HTML-representationen av data.
För att se hur slumpmässiga strängdata representeras i HTML, välj slumpmässiga strängdata och tryck på höger musknapp (RMB) och klicka på Inspektera element (Q), som noterad i skärmdumpen nedan.
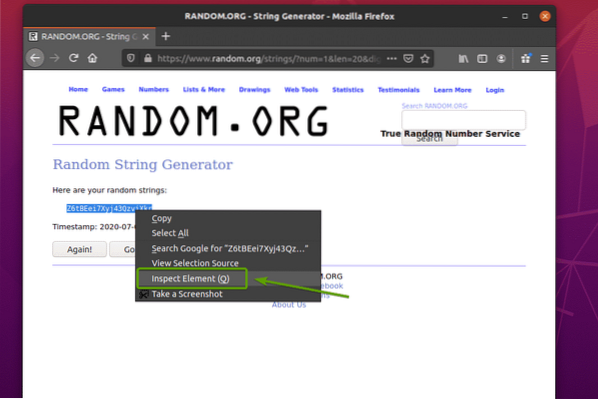
HTML-representationen av data ska visas i Inspektör fliken, som du kan se på skärmdumpen nedan.
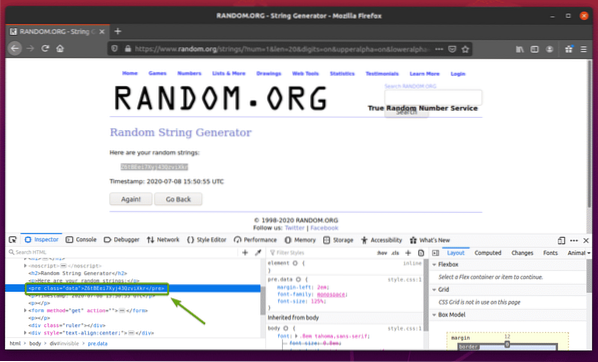
Du kan också klicka på Inspektera ikonen ( ) för att inspektera data från sidan.
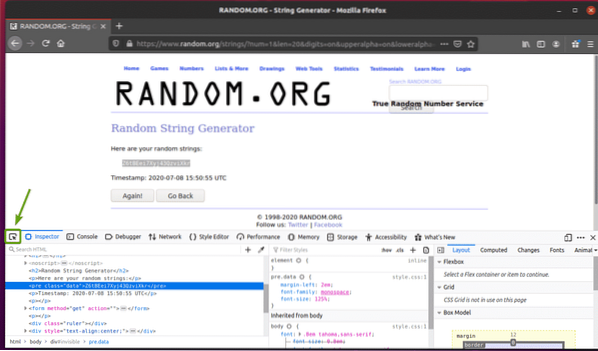
Klicka på inspekteringsikonen () och håll muspekaren över slumpmässiga strängdata som du vill extrahera. HTML-representationen av data ska visas som tidigare.
Som du kan se slumpmässiga strängdata inslagna i en HTML före tagg och innehåller klassen data.
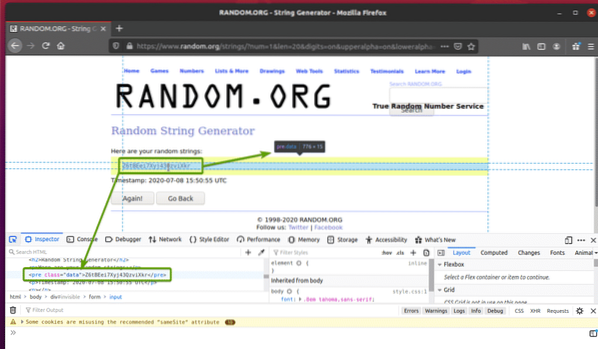
Nu när vi känner till HTML-representationen av de data vi vill extrahera skapar vi ett Python-skript för att extrahera data med Selen.
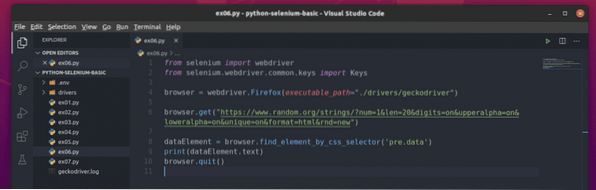
Skapa det nya Python-skriptet ex06.py och skriv följande koderader i skriptet
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.få ("https: // www.slumpmässig.org / strängar /?num = 1 & len = 20 & siffror
= on & upperalpha = on & loweralpha = on & unique = on & format = html & rnd = new ")
dataElement = webbläsare.find_element_by_css_selector ('pre.data')
skriva ut (dataElement.text)
webbläsare.sluta()
När du är klar sparar du ex06.py Python-skript.
Här, den webbläsare.skaffa sig() metoden laddar webbsidan i Firefox-webbläsaren.

De webbläsare.find_element_by_css_selector () metoden söker efter HTML-koden på sidan efter ett specifikt element och returnerar den.
I det här fallet skulle elementet vara före.data, de före tagg som har klassnamnet data.
Under före.data har lagrats i dataElement variabel.

Skriptet skriver sedan ut textinnehållet för det valda före.data element.

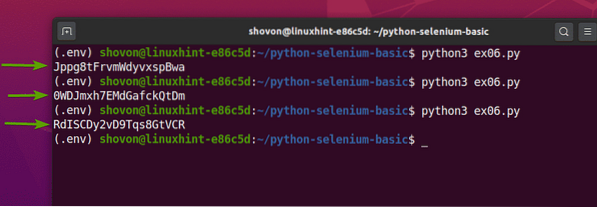
Om du kör ex06.py Python-skript, det borde extrahera slumpmässiga strängdata från webbsidan, som du kan se på skärmdumpen nedan.
$ python3 ex06.py
Som du kan se, varje gång jag kör ex06.py Python-skript, det extraherar en annan slumpmässig strängdata från webbsidan.
Exempel 4: Extrahera lista över data från webbsidan
Det föregående exemplet visade hur du extraherar ett enda dataelement från en webbsida med Selen. I det här exemplet visar jag hur du använder Selen för att extrahera en lista med data från en webbsida.
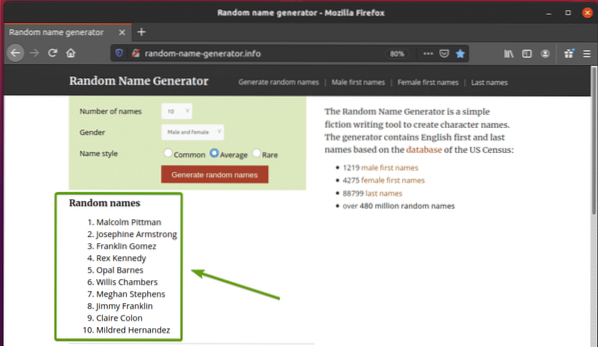
Besök först random-name-generator.info från din Firefox-webbläsare. Denna webbplats genererar tio slumpmässiga namn varje gång du laddar om sidan, som du kan se på skärmdumpen nedan. Vårt mål är att extrahera dessa slumpmässiga namn med hjälp av Selen.
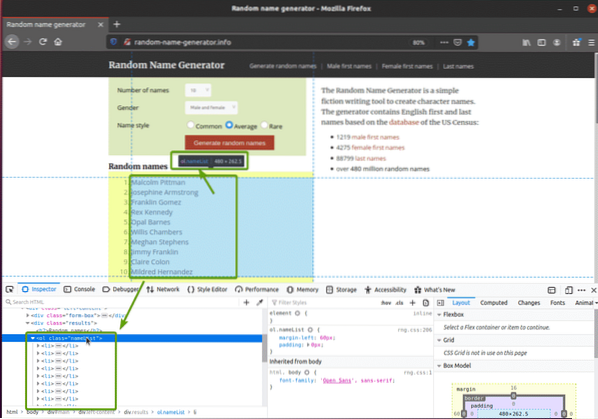
Om du inspekterar namnlistan närmare kan du se att det är en ordnad lista (ol märka). De ol taggen innehåller också klassnamnet namnlista. Varje slumpmässigt namn representeras som ett listobjekt (li tag) inuti ol märka.
Skapa det nya Python-skriptet för att extrahera dessa slumpmässiga namn ex07.py och skriv följande koderader i skriptet.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.get ("http: // random-name-generator.info/")
nameList = webbläsare.find_elements_by_css_selector ('ol.nameList li ')
för namn i namnLista:
Skriv namn.text)
webbläsare.sluta()
När du är klar sparar du ex07.py Python-skript.
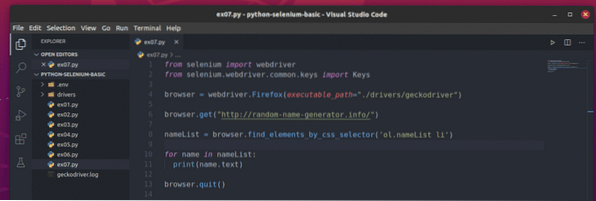
Här, den webbläsare.skaffa sig() metoden laddar webbsidan för slumpmässiga namngeneratorer i webbläsaren Firefox.

De webbläsare.find_elements_by_css_selector () metoden använder CSS-väljaren ol.namnLista li för att hitta alla li element inuti ol tagg med klassnamnet namnlista. Jag har lagrat alla valda li element i namnlista variabel.

A för loop används för att iterera genom namnlista lista av li element. I varje iteration, innehållet i li elementet skrivs ut på konsolen.

Om du kör ex07.py Python-skript, det kommer att hämta alla slumpmässiga namn från webbsidan och skriva ut det på skärmen, som du kan se på skärmdumpen nedan.
$ python3 ex07.py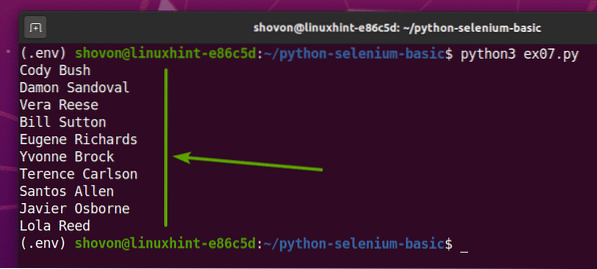
Om du kör skriptet en andra gång ska det returnera en ny lista med slumpmässiga användarnamn, som du kan se på skärmdumpen nedan.
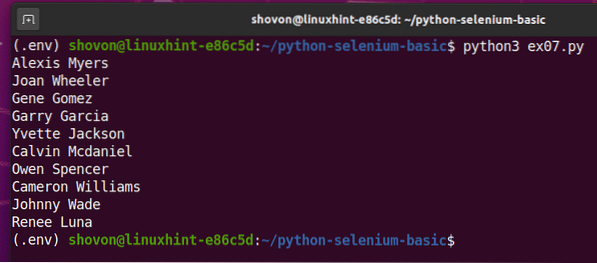
Exempel 5: Skicka formulär - Söka på DuckDuckGo
Detta exempel är lika enkelt som det första exemplet. I det här exemplet kommer jag att besöka DuckDuckGo-sökmotorn och söka efter termen selen hq med Selen.
Besök först DuckDuckGo-sökmotorn från webbläsaren Firefox.
Om du inspekterar sökinmatningsfältet ska det ha id search_form_input_homepage, som du kan se på skärmdumpen nedan.
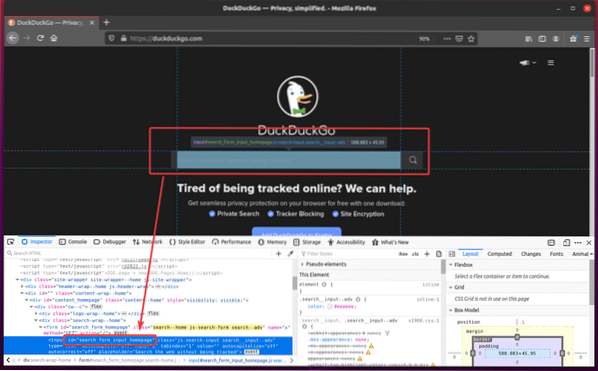
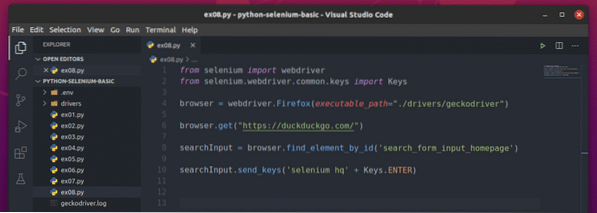
Skapa nu det nya Python-skriptet ex08.py och skriv följande koderader i skriptet.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.get ("https: // duckduckgo.com / ")
searchInput = webbläsare.find_element_by_id ('search_form_input_homepage')
searchInput.send_keys ('selen hq' + nycklar.STIGA PÅ)
När du är klar sparar du ex08.py Python-skript.
Här, den webbläsare.skaffa sig() metoden laddar hemsidan för DuckDuckGo-sökmotorn i webbläsaren Firefox.

De webbläsare.find_element_by_id () metoden väljer ingångselementet med id search_form_input_homepage och lagrar den i searchInput variabel.

De searchInput.send_keys () metoden används för att skicka knapptrycksdata till inmatningsfältet. I det här exemplet skickar den strängen selen hq, och Enter-tangenten trycks in med Nycklar.STIGA PÅ konstant.
Så snart DuckDuckGo-sökmotorn tar emot Enter-tangenten (Nycklar.STIGA PÅ), det söker och visar resultatet.

Springa det ex08.py Python-skript, enligt följande:
$ python3 ex08.py
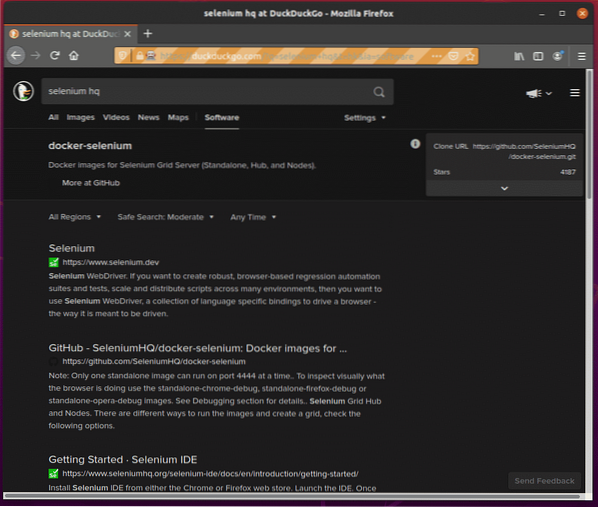
Som du kan se besökte Firefox-webbläsaren DuckDuckGo-sökmotorn.

Det skrivs automatiskt selen hq i söktextrutan.

Så snart webbläsaren fick Enter-tangenten trycker du på (Nycklar.STIGA PÅ), det visade sökresultatet.
Exempel 6: Skicka ett formulär på W3Schools.com
I exempel 5 var det enkelt att lämna in formulär från DuckDuckGo-sökmotorer. Allt du behöver göra var att trycka på Enter. Men detta kommer inte att vara fallet för alla formulärinlämningar. I det här exemplet visar jag dig mer komplex formulärhantering.
Besök först HTML-formulärssidan för W3Schools.com från webbläsaren Firefox. När sidan har laddats bör du se ett exempelformulär. Det här är formuläret vi skickar in i det här exemplet.
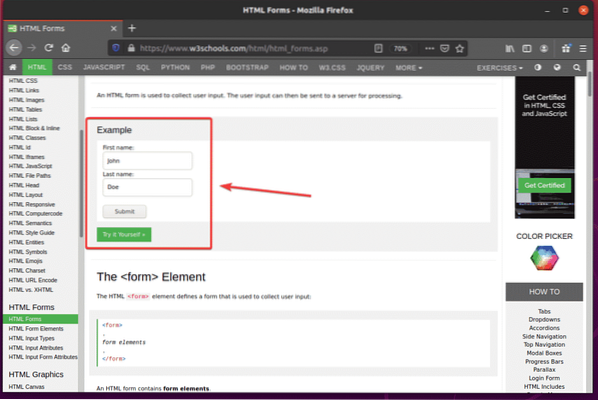
Om du inspekterar formuläret, Förnamn inmatningsfältet ska ha id fname, de Efternamn inmatningsfältet ska ha id lname, och den Skickaknapp borde ha typ Skicka in, som du kan se på skärmdumpen nedan.
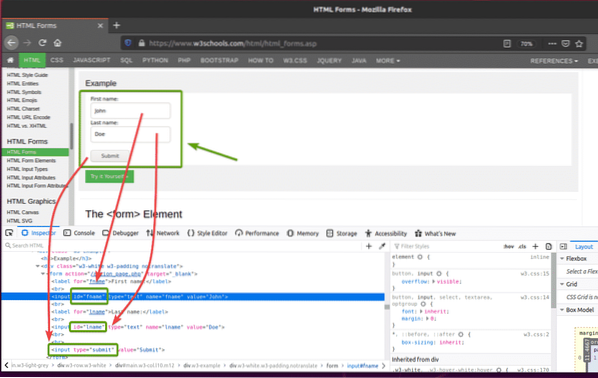
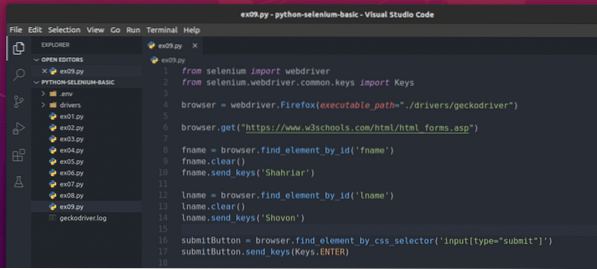
Skapa det nya Python-skriptet för att skicka det här formuläret med Selenium ex09.py och skriv följande koderader i skriptet.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
webbläsare = webdriver.Firefox (executable_path = "./ drivrutiner / geckodriver ")
webbläsare.få ("https: // www.w3schools.com / html / html_forms.asp")
fname = webbläsare.find_element_by_id ('fname')
fname.klar()
fname.send_keys ('Shahriar')
lname = webbläsare.find_element_by_id ('lname')
lname.klar()
lname.send_keys ('Shovon')
submitButton = webbläsare.find_element_by_css_selector ('input [type = "submit"]')
skickaknapp.send_keys (nycklar.STIGA PÅ)
När du är klar sparar du ex09.py Python-skript.
Här, den webbläsare.skaffa sig() metoden öppnar sidan W3schools HTML-formulär i webbläsaren Firefox.

De webbläsare.find_element_by_id () metoden hittar inmatningsfälten efter id fname och lname och det lagrar dem i fname och lname variabler.


De fname.klar() och lname.klar() metoder rensar standardnamnet (John) fname värde och efternamn (Doe) lname värde från inmatningsfälten.


De fname.send_keys () och lname.send_keys () metodtyp Shahriar och Shovon i Förnamn och Efternamn inmatningsfält, respektive.


De webbläsare.find_element_by_css_selector () metoden väljer Skickaknapp av formuläret och lagrar det i skickaknapp variabel.

De skickaknapp.send_keys () metoden skickar Enter-tangenten (Nycklar.STIGA PÅ) till Skickaknapp av formuläret. Denna åtgärd skickar in formuläret.

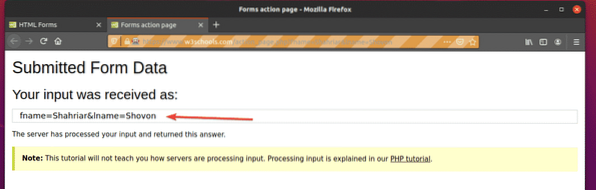
Springa det ex09.py Python-skript, enligt följande:
$ python3 ex09.py
Som du ser har formuläret skickats automatiskt med rätt inmatningar.
Slutsats
Den här artikeln ska hjälpa dig att komma igång med Selenium-webbläsartestning, webbautomation och skrotningsbibliotek i Python 3. För mer information, kolla in den officiella Selenium Python-dokumentationen.


