dd-funktioner
"Dd" kan användas för olika ändamål:
- Med hjälp av “dd” är det möjligt att direkt läsa och / eller skriva från / till olika filer förutsatt att funktionen redan är implementerad i respekterade drivrutiner.
- Det är super användbart för ändamål som att säkerhetskopiera startsektorn, få slumpmässiga data etc.
- Datakonvertering, till exempel konvertering av ASCII till EBCDIC-kodning.
dd-användning
Här är några av de vanligaste och mest intressanta användningarna av “dd”. Naturligtvis är "dd" mycket mer kapabel än dessa saker. Om du är intresserad rekommenderar jag alltid att du tittar på andra fördjupade resurser på “dd”.
Plats
vilken dd
Som utgången indikerar startar den från "/ usr / bin / dd" när du kör "dd".
Grundläggande användning
Här är strukturen som "dd" följer.
dd if =Låt oss till exempel skapa en fil med slumpmässiga data. Det finns några inbyggda specialfiler i Linux som visas som vanliga filer som "/ dev / zero" som ger en kontinuerlig ström av NULL, "/ dev / random" som ger kontinuerlig slumpmässig data.
dd if = / dev / urandom of = ~ / Desktop / random.txt bs = 1M antal = 5
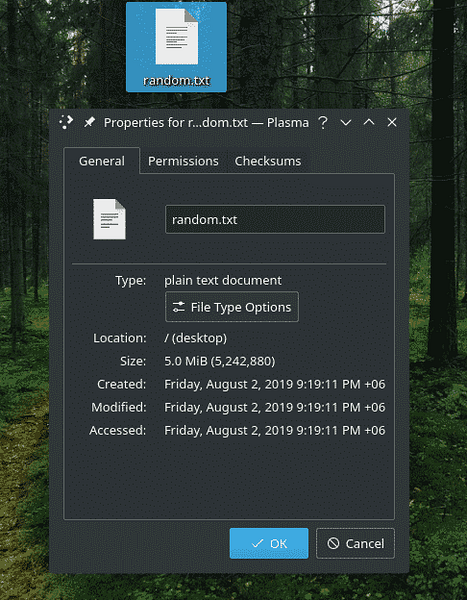
De allra första alternativen är självförklarande. Det betyder att använda “/ dev / urandom” som en datakälla och “~ / Desktop / random.txt ”som destination. Vilka är de andra alternativen?
Här står "bs" för "blockstorlek". När dd skriver data skriver den i block. Med detta alternativ kan blockstorleken definieras. I detta fall säger värdet “1M” att blockstorleken är 1 megabyte.
"Räkna" bestämmer antalet block som ska skrivas. Om det inte fixas fortsätter "dd" skrivprocessen såvida inte inmatningsströmmen slutar. I det här fallet fortsätter "/ dev / urandom" att generera data oändligt, så detta alternativ var avgörande i detta exempel.
Säkerhetskopiering av data
Med den här metoden kan "dd" användas för att dumpa data för en hel enhet! Allt du behöver är att berätta om enheten som källa.
dd if =
Om du vill göra sådana åtgärder, se till att din källa inte är en katalog. “Dd” har ingen aning om hur en katalog ska bearbetas, så saker och ting fungerar inte.

“Dd” vet bara hur man arbetar med filer. Så om du behöver säkerhetskopiera en katalog, använd tar för att arkivera den först och använd sedan "dd" för att överföra den till en fil.
tar cvJf demo.tjära.xz DemoDir /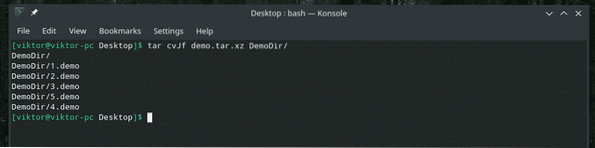

I nästa exempel kommer vi att utföra en mycket känslig operation: säkerhetskopiera MBR! Nu, om ditt system använder MBR (Master Boot Record), ligger det vid de första 512 bytes på systemdisken: 466 byte för bootloader, andra för partitionstabellen.
Kör det här kommandot för att säkerhetskopiera MBR-posten.
dd if = / dev / sda of = ~ / Desktop / mbr.img bs = 512 antal = 1
Dataåterställning
För varje säkerhetskopia är sättet att återställa data nödvändigt. I fallet med "dd" är återställningsprocessen lite annorlunda än andra verktyg. Du måste skriva om säkerhetskopian på en liknande mapp / partition / enhet.
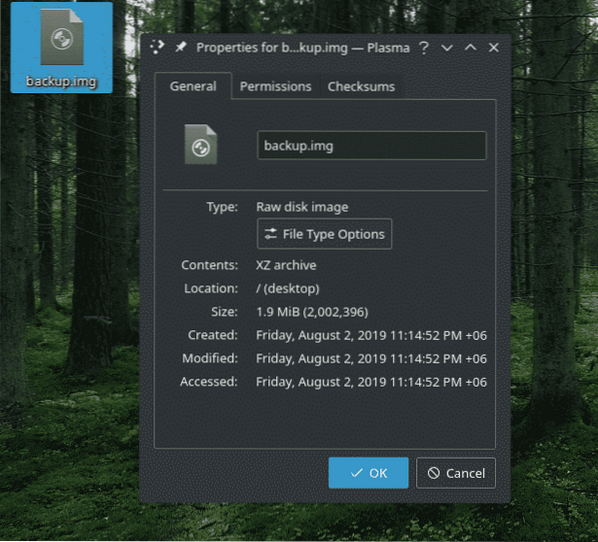
Till exempel har jag den här "säkerhetskopian.img-fil som innehåller "demo.tjära.xz ”-fil. För att extrahera det använde jag följande kommando.
dd if = säkerhetskopia.img av = demo.tjära.xz
Återigen, se till att du skriver utdata till en fil. "Dd" är inte bra med kataloger, kom ihåg?
På samma sätt, om “dd” användes för att skapa en säkerhetskopia av en partition, skulle följande kommando krävas för att återställa den.
dd if =
Till exempel vad sägs om att återställa MBR som vi säkerhetskopierade tidigare?
dd if = mbr.bild av = / dev / sda
"Dd" -alternativ
Vid någon tidpunkt i den här guiden stod du inför några "dd" -alternativ som "bs" och "count", eller hur? Det finns fler av dem. Här är en kortlista om vad de är och hur man använder dem.
- obs: Bestämmer storleken på data som ska skrivas åt gången. Standardvärdet är 512 byte.

- cbs: Bestämmer storleken på data som ska konverteras åt gången.

- ibs: Bestämmer storleken på data som ska läsas åt gången.
- count: Kopiera endast N-block

- sök: Hoppa över N-block i början av utgången

- hoppa över: Hoppa över N-block i början av inmatningen







Ytterligare alternativ:
- nocreat: Skapa inte utdatafilen
- notruc: Avkorta inte utdatafilen
- noerror: Fortsätt operationen, även efter att ha uppstått fel
- fdatasync: Skriv data till den fysiska lagringen innan processen är klar
- fsync: Liknar fdatasync, men skriver också metadata
- iflag: Justera operationen baserat på olika flaggor. Tillgängliga flaggor inkluderar: lägg till Lägg till data till utdata

Ytterligare alternativ:
- katalog: Att möta en katalog misslyckas med åtgärden
- dsync: Synkroniserad I / O för data
- sync: Liknar dsync men innehåller metadata
- nocache: Begäran om att tappa cache.
- nofollow: Följ inte någon symlink

Ytterligare alternativ:
- count_bytes: Liknar "count = N"
- seek_bytes: Liknar “seek = N”
- skip_bytes: Liknar "skip = N"
Som du har sett är det möjligt att stapla flera flaggor och alternativ i ett enda “dd” -kommando för att justera funktionsbeteendet.
dd if = demo.txt av = demo1.txt bs = 10 räkna = 100 conv = ebcdiciflag = append, nocache, nofollow, sync

Slutgiltiga tankar
Arbetsflödet för “dd” är ganska enkelt. Men för att "dd" verkligen ska lysa, är det upp till dig. Det finns många sätt kreativa sätt "dd" kan användas för att utföra smarta interaktioner.
För detaljerad information om “dd” och alla dess alternativ, se man- och infosidan.
man dd

