Till exempel kan ett företag driva en textanalysmotor som behandlar tweets om sin verksamhet som nämner företagsnamn, plats, process och analyserar känslor relaterade till den tweeten. Korrekta åtgärder kan vidtas snabbare om företaget lär sig om att växa negativa tweets för det på en viss plats för att rädda sig från ett misstag eller något annat. Ett annat vanligt exempel är för Youtube. Youtube-administratörer och moderatorer lär känna effekten av en video beroende på vilken typ av kommentarer som görs på en video eller videochattmeddelandena. Detta kommer att hjälpa dem att hitta olämpligt innehåll på webbplatsen mycket snabbare för nu har de utrotat det manuella arbetet och använt automatiserade smarta textanalysbots.
I den här lektionen kommer vi att studera några av begreppen relaterade till textanalys med hjälp av NLTK-biblioteket i Python. Några av dessa begrepp kommer att involvera:
- Tokenisering, hur man delar upp en text i ord, meningar
- Undvik stoppord baserat på engelska
- Utföra stemming och lemmatisering på en bit text
- Identifiera de tokens som ska analyseras
NLP kommer att vara huvudfokusområdet i den här lektionen eftersom det är tillämpligt på enorma verkliga scenarier där det kan lösa stora och avgörande problem. Om du tycker att det här låter komplext, så gör det det, men begreppen är lika lätta att förstå om du försöker exempel sida vid sida. Låt oss hoppa över att installera NLTK på din maskin för att komma igång med det.
Installerar NLTK
Bara en anteckning innan du börjar kan du använda en virtuell miljö för den här lektionen som vi kan göra med följande kommando:
python -m virtualenv nltkkälla nltk / bin / aktivera
När den virtuella miljön är aktiv kan du installera NLTK-biblioteket i det virtuella env så att exempel vi skapar nästa kan köras:
pip install nltkVi kommer att använda Anaconda och Jupyter i den här lektionen. Om du vill installera den på din maskin, titta på lektionen som beskriver ”Hur man installerar Anaconda Python på Ubuntu 18.04 LTS ”och dela din feedback om du står inför några problem. För att installera NLTK med Anaconda, använd följande kommando i terminalen från Anaconda:
conda install -c anaconda nltkVi ser något liknande när vi utför ovanstående kommando:
När alla paket som behövs är installerade och klara kan vi komma igång med att använda NLTK-biblioteket med följande importuttalande:
importera nltkLåt oss komma igång med grundläggande NLTK-exempel nu när vi har förutsättningspaket installerat.
Tokenisering
Vi börjar med Tokenization som är det första steget i att utföra textanalys. En token kan vara vilken som helst mindre del av en bit text som kan analyseras. Det finns två typer av tokenisering som kan utföras med NLTK:
- Meningstokenisering
- Word Tokenization
Du kan gissa vad som händer på var och en av tokeniseringen, så låt oss dyka in i kodexempel.
Meningstokenisering
Som namnet speglar bryter Sentence Tokenizers en bit text i meningar. Låt oss prova ett enkelt kodavsnitt för detsamma där vi använder en text som vi valde från Apache Kafka tutorial. Vi kommer att utföra nödvändig import
importera nltkfrån nltk.tokenize import sent_tokenize
Observera att du kan stöta på ett fel på grund av att beroendet för nltk saknas punkt. Lägg till följande rad direkt efter importen i programmet för att undvika varningar:
nltk.ladda ner ('punkt')För mig gav det följande resultat:
Därefter använder vi meningen tokenizer vi importerade:
text = "" "Ett ämne i Kafka är något där ett meddelande skickas. Konsumentenapplikationer som är intresserade av det ämnet drar meddelandet inuti det
ämne och kan göra vad som helst med den informationen. Upp till en viss tid, valfritt antal
konsumentapplikationer kan dra detta meddelande valfritt antal gånger."" "
meningar = sent_tokenize (text)
skriva ut (meningar)
Vi ser något så här när vi kör ovanstående skript:

Som förväntat var texten ordentligt ordnad i meningar.
Word Tokenization
Som namnet återspeglar delar Word Tokenizers en text i ord. Låt oss prova ett enkelt kodavsnitt för samma med samma text som föregående exempel:
från nltk.tokenize import word_tokenizeord = word_tokenize (text)
skriva ut (ord)
Vi ser något så här när vi kör ovanstående skript:

Som förväntat var texten ordnat ordentligt.
Frekvensfördelning
Nu när vi har brutit texten kan vi också beräkna frekvensen för varje ord i texten vi använde. Det är väldigt enkelt att göra med NLTK, här är kodavsnittet vi använder:
från nltk.sannolikhetsimport FreqDistdistribution = FreqDist (ord)
skriva ut (distribution)
Vi ser något så här när vi kör ovanstående skript:

Därefter kan vi hitta de vanligaste orden i texten med en enkel funktion som accepterar antalet ord som ska visas:
# Vanligaste orddistribution.most_common (2)
Vi ser något så här när vi kör ovanstående skript:

Slutligen kan vi skapa en frekvensfördelningsdiagram för att rensa orden och deras antal i den givna texten och tydligt förstå fördelningen av ord:

Stoppord
Precis som när vi pratar med en annan person via ett samtal, tenderar det att vara lite buller över samtalet som är oönskad information. På samma sätt innehåller text från verkliga världen också buller som kallas Stoppord. Stoppord kan variera från språk till språk men de kan lätt identifieras. Några av stopporden på engelska kan vara - är, är, a, en, etc.
Vi kan titta på ord som betraktas som stoppord av NLTK för engelska med följande kodavsnitt:
från nltk.stoppord för corpusimportnltk.ladda ner ('stoppord')
språk = "engelska"
stop_words = set (stoppord.ord (språk))
skriv ut (stoppord)
Eftersom uppsättningen stoppord naturligtvis kan vara stor lagras den som en separat dataset som kan laddas ner med NLTK som vi har visat ovan. Vi ser något så här när vi kör ovanstående skript:
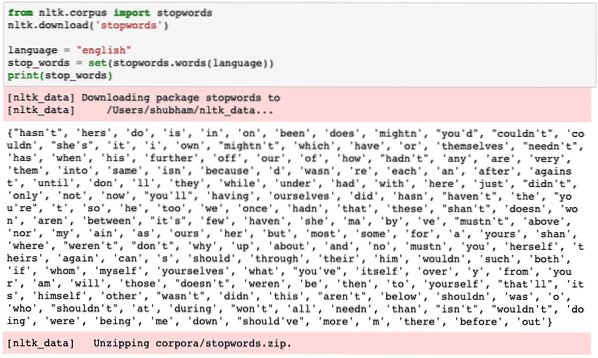
Dessa stoppord bör tas bort från texten om du vill göra en exakt textanalys för den text som tillhandahålls. Låt oss ta bort stopporden från våra textuella tokens:
filtered_words [[]för ord i ord:
om ordet inte finns i stoppord:
filtered_words.bifoga (ord)
filtered_words
Vi ser något så här när vi kör ovanstående skript:

Word Stemming
En stam av ett ord är basen för det ordet. Till exempel:
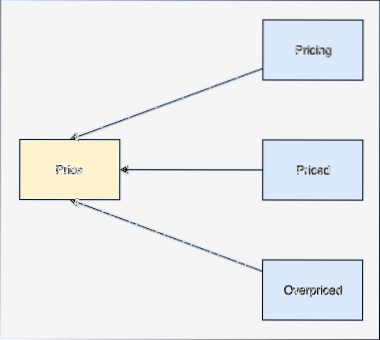
Vi kommer att utföra som härstammar från de filtrerade orden från vilka vi tog bort stoppord i det sista avsnittet. Låt oss skriva ett enkelt kodavsnitt där vi använder NLTK: s stemmer för att utföra operationen:
från nltk.stamimport PorterStemmerps = PorterStemmer ()
stammed_words = []
för ord i filtrerade_ord:
stammed_words.bifoga (ps.stam (ord))
print ("Stemmed Sentence:", stemmed_words)
Vi ser något så här när vi kör ovanstående skript:

POS-märkning
Nästa steg i textanalys är efter stemming att identifiera och gruppera varje ord i termer av deras värde, dvs.e. om vart och ett av ordet är ett substantiv eller verb eller något annat. Detta kallas som en del av talmärkning. Låt oss utföra POS-märkning nu:
tokens = nltk.word_tokenize (meningar [0])skriva ut (tokens)
Vi ser något så här när vi kör ovanstående skript:

Nu kan vi utföra taggningen, för vilken vi måste ladda ner en annan dataset för att identifiera rätt taggar:
nltk.ladda ner ('averaged_perceptron_tagger')nltk.pos_tag (tokens)
Här är resultatet av märkningen:
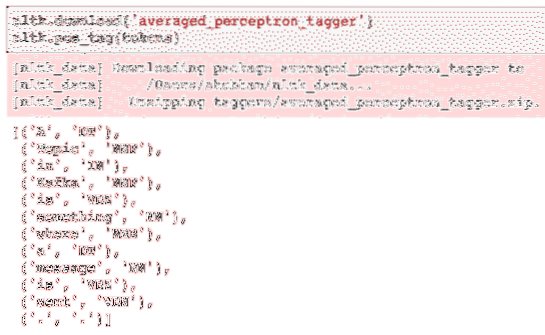
Nu när vi äntligen har identifierat de taggade orden är detta den dataset som vi kan utföra sentimentanalys för att identifiera känslorna bakom en mening.
Slutsats
I den här lektionen tittade vi på ett utmärkt naturligt språkpaket, NLTK som låter oss arbeta med ostrukturerad textinformation för att identifiera eventuella stoppord och utföra djupare analyser genom att förbereda en skarp datamängd för textanalys med bibliotek som sklearn.
Hitta all källkod som används i den här lektionen på Github. Dela din feedback om lektionen på Twitter med @sbmaggarwal och @LinuxHint.

