För att förstå begreppet fulltext-sökning måste du komma ihåg kunskap om mönstersökning via nyckelordet LIKE. Så låt oss anta en tabell 'person' i databasens 'test' med följande poster i den.
>> VÄLJ * FRÅN person;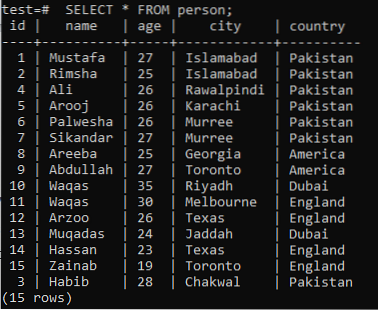
Låt oss anta att du vill hämta posterna i den här tabellen, där kolumnen "namn" har tecknet "i" i något av dess värden. Prova nedanstående SELECT-fråga när du använder LIKE-satsen i kommandoskalet. Från utdata nedan kan du se att vi bara har 5 poster för just detta tecken "i" i kolumnen "namn".
>> VÄLJ * FRÅN person VAR namn LIKE '% i%';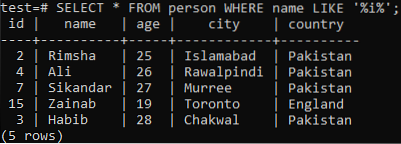
Användning av Tvsector:
Ibland är det ingen nytta att använda LIKE Keyword för att göra en snabb mönstersökning, även om ordet finns där. Du kanske överväger att använda standarduttryck, och även om detta är ett genomförbart alternativ, är reguljära uttryck både starka och tröga. Att ha en procedurvektor för hela ord i en text, en språklig beskrivning av dessa ord, är ett mycket mer effektivt sätt att ta itu med denna fråga. Begreppet fullständig textsökning och datatypen tsvector skapades för att svara på den. Det finns två metoder i PostgreSQL som gör precis vad vi vill:
- To_tvsector: Används för att skapa en lista över tokens (ts betyder för "textsökning").
- To_tsquery: Används för att söka i vektorn efter förekomster av specifika termer eller fraser.
Exempel 01:
Låt oss börja med en enkel illustration av att skapa en vektor. Antag att du vill skapa en vektor för strängen: ”Vissa människor har lockigt brunt hår genom korrekt borstning.”. Så du måste skriva en to_tvsector () -funktion tillsammans med denna mening inom parenteserna för en SELECT-fråga som bifogas nedan. Från utdata nedan kan du se att det skulle ge en referensvektor (filpositioner) för varje token, och även där termer med lite sammanhang, som artiklar (the) och konjunktioner (och, eller), avsiktligt ignoreras.
>> VÄLJ till_tsvector ("Vissa människor har lockigt bruna hår genom korrekt borstning");
Exempel 02:
Antag att du har två dokument med en del data i båda. För att lagra dessa data kommer vi nu att använda ett verkligt exempel på att generera tokens. Antag att du har skapat en tabell "Data" i din databas "test" med några kolumner i den med hjälp av nedanstående CREATE TABLE-fråga. Glöm inte att skapa en TVSECTOR-kolumn med namnet 'token' i den. Från utdata nedan kan du titta på tabellen som har skapats.
>> CREATE TABLE Data (Id SERIAL PRIMARY KEY, info TEXT, token TSVECTOR);
Nu blir det för oss att lägga till den totala informationen för båda dokumenten i denna tabell. Så prova INSERT-kommandot nedan i kommandoradsskalet för att göra det. Slutligen har posterna från båda dokumenten lagts till i tabellen 'Data'.
>> INSERT INTO Data (info) VÄRDEN ('Två fel kan aldrig göra en rätt.'), (' Han är den som kan spela fotboll.'), (' Kan jag spela en roll i detta?'), (' Smärtan inuti en kan inte förstås '), (' Ta med persika i ditt liv);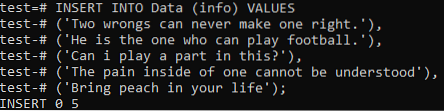
Nu måste du kolonisera token-kolumnen för båda dokumenten med deras specifika vektor. I slutändan fyller en enkel UPDATE-fråga kolumnen tokens med motsvarande vektor för varje fil. Så du måste utföra den angivna frågan nedan i kommandoskalet för att göra det. Resultatet visar att uppdateringen äntligen har gjorts.
>> UPPDATERA data f1 SET token = to_tsvector (f1.info) FRÅN Data f2;
Nu när vi har allt på plats, låt oss återgå till vår illustration av "kan man" med en skanning. Att to_tsquery med AND-operatören, som tidigare sagt, gör ingen skillnad mellan filernas platser i filerna som visas från utdata som anges nedan.
>> VÄLJ Id, info FRÅN Data VAR token @@ till_tsquery ('kan & en');
Exempel 04:
För att hitta ord som är "bredvid" varandra, försöker vi samma fråga med '<->operatör. Ändringen visas i utdata nedan.
>> VÄLJ Id, info FRÅN Data VAR token @@ till_tsquery ('kan <-> ett');
Här är ett exempel på inget omedelbart ord bredvid ett annat.
>> VÄLJ Id, info FRÅN Data VAR token @@ till_tsquery ('en <-> smärta');
Exempel 05:
Vi hittar orden som inte är direkt bredvid varandra genom att använda ett nummer i avståndsoperatören för att referera till avstånd. Närheten mellan "bring" och "life är fyra ord förutom den visade bilden.
>> VÄLJ * FRÅN Data VAR token @@ till_tsquery ('bring <4> liv');
För att kontrollera närheten mellan orden för nästan 5 ord läggs nedan.
>> VÄLJ * FRÅN Data VAR token @@ till_tsquery ('fel <5> rätt');
Slutsats:
Slutligen har du gjort alla enkla och komplicerade exempel på fulltextsökning med To_tvsector och to_tsquery-operatörer och funktioner.


