Detta har en innebörd. Dess innebörd är att det finns många användbara data på Google och det kräver ett behov av att skrapa denna gyllene data. De skrapade uppgifterna kan användas för analys av kvalitetsdata och för att upptäcka underbara insikter. Det kan också vara viktigt att få bra forskningsinformation i ett försök.
När vi pratar om skrapning kan detta göras med verktyg från tredje part. Det kan också göras med ett Python-bibliotek som kallas Scrapy. Scrapy klassas som ett av de bästa skrapverktygen och kan användas för att skrapa nästan vilken webbsida som helst. Du kan ta reda på mer på Scrapy-biblioteket.
Men oavsett styrkan i detta underbara bibliotek. Skrapa data på Google kan vara en svår uppgift. Google kommer hårt ner på alla webbskrapningsförsök och ser till att skrapskript inte ens gör så många 10 skrapförfrågningar på en timme innan IP-adressen förbjuds. Detta gör tredjeparts och personliga webbskrapningsskript värdelösa.
Google ger möjlighet att skrapa information. Oavsett skrapning som skulle göras måste det ske via ett API (Application Programming Interface).
Om du inte redan vet vad ett applikationsprogrammeringsgränssnitt är, finns det inget att oroa sig för då jag ger en kort förklaring. Per definition är ett API en uppsättning funktioner och procedurer som gör det möjligt att skapa applikationer som får åtkomst till funktionerna eller data i ett operativsystem, applikation eller annan tjänst. I grund och botten låter ett API dig få tillgång till slutresultatet av processer utan att behöva vara involverad i dessa processer. Till exempel skulle ett temperatur-API ge dig Celsius / Fahrenheit-värdena för en plats utan att du behöver gå dit med en termometer för att göra mätningarna själv.
Om vi tar detta in i räckvidden för skrapinformation från Google, ger API: n vi använder oss tillgång till den information som behövs utan att behöva skriva något skript för att skrapa resultatsidan för en Google-sökning. Via API kan vi helt enkelt få tillgång till slutresultatet (efter att Google gör "skrapningen" i slutet) utan att skriva någon kod för att skrapa webbsidor.
Medan Google har massor av API: er för olika ändamål, kommer vi att använda JSON API för anpassad sökning för denna artikel. Mer information om detta API finns här.
Med detta API kan vi göra 100 sökfrågor per dag gratis, med prissättningsplaner tillgängliga för att göra fler frågor om det behövs.
Skapa en anpassad sökmotor
För att kunna använda JSON API för anpassad sökning skulle vi behöva ett anpassat sökmotor-ID. Men vi måste först skapa en anpassad sökmotor som kan göras här.
När du besöker sidan Anpassad sökmotor klickar du på knappen "Lägg till" för att skapa en ny sökmotor.
I rutan "webbplatser att söka", helt enkelt sätta i "www.linuxhint.com "och i rutan" Namn på sökmotorn ", lägg in ett valfritt beskrivande namn (Google skulle vara att föredra).
Klicka nu på "Skapa" för att skapa den anpassade sökmotorn och klicka på "kontrollpanel" -knappen från sidan för att bekräfta framgången med skapandet.
Du skulle se avsnittet "Sökmotor-ID" och ett ID under det, det är det ID vi skulle behöva för API: et och vi hänvisar till det senare i den här självstudien. Sökmotor-ID: t ska hållas privat.
Innan vi åker, kom ihåg att vi lägger in ”www.linuhint.com ”tidigare. Med den inställningen skulle vi bara få resultat från webbplatsen ensam. Om du vill få de normala resultaten från den totala webbsökningen, klicka på "Inställning" i menyn till vänster och klicka sedan på fliken "Grundläggande". Gå till avsnittet "Sök på hela webben" och slå på den här funktionen.

Skapa en API-nyckel
Efter att du har skapat en anpassad sökmotor och fått sitt ID skulle nästa vara att skapa en API-nyckel. API-nyckeln ger åtkomst till API-tjänsten, och den ska hållas säker efter skapandet precis som sökmotor-ID.
För att skapa en API-nyckel, besök webbplatsen och klicka på knappen "Få en nyckel".
Skapa ett nytt projekt och ge det ett beskrivande namn. När du klickar på ”nästa” skulle API-nyckeln genereras.
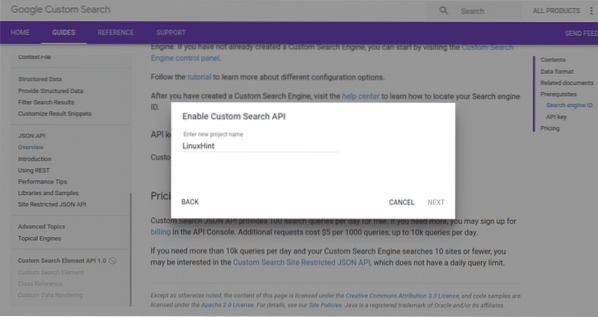
På nästa sida skulle vi ha olika inställningsalternativ som inte är nödvändiga för den här självstudien, så du klickar bara på knappen "spara" så är vi redo att gå.
Åtkomst till API
Vi har gjort det bra med att få Custom Search ID och API Key. Därefter kommer vi att använda API: et.
Medan du kan komma åt API med andra programmeringsspråk, kommer vi att göra det med Python.
För att kunna komma åt API: et med Python måste du installera Google API-klienten för Python. Detta kan installeras med pipinstallationspaketet med kommandot nedan:
pip installera google-api-python-clientEfter installationen kan du nu importera biblioteket i vår kod.
Det mesta av vad som kommer att göras skulle ske genom funktionen nedan:
från googleapiclient.uppbyggnad av upptäcktsimportmy_api_key = "Din API-nyckel"
my_cse_id = "Ditt CSE-ID"
def google_search (search_term, api_key, cse_id, ** kwargs):
service = build ("tullsökning", "v1", developerKey = api_key)
res = tjänst.cse ().lista (q = sök_term, cx = cse_id, ** kwargs).Kör()
returres
I funktionen ovan är my_api_key och min_cse_id variabler bör ersättas av API-nyckeln respektive sökmotor-ID som strängvärden.
Allt som behöver göras nu är att anropa funktionen som passerar i söktermen, api-tangenten och cse-id.
resultat = google_search ("Kaffe", min_api_nyckel, min_cse_id)skriva ut (resultat)
Funktionsanropet ovan skulle söka efter nyckelordet "Kaffe" och tilldela det returnerade värdet till resultat variabel, som sedan skrivs ut. Ett JSON-objekt returneras av Custom Search API, varför ytterligare analys av det resulterande objektet kräver lite kunskap om JSON.
Detta kan ses från ett urval av resultatet enligt nedan:
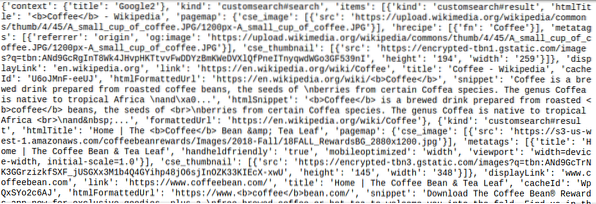
JSON-objektet som returneras ovan liknar mycket resultatet från Google-sökningen:
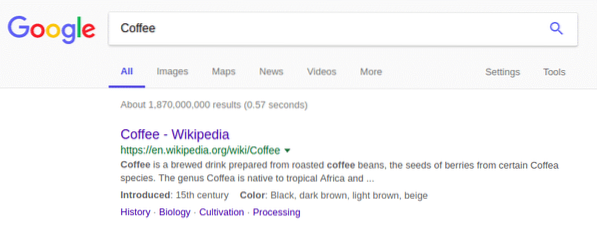
Sammanfattning
Att skrapa Google för information är inte riktigt värt stress. API för anpassad sökning gör livet enkelt för alla, eftersom den enda svårigheten är att analysera JSON-objektet för den information som behövs. Som en påminnelse, kom alltid ihåg att hålla ditt anpassade sökmotor-ID och API-nyckelvärden privata.


