Att hitta och välja element från webbsidan är nyckeln till webbskrapning med Selen. För att hitta och välja element från webbsidan kan du använda XPath-väljare i Selenium.
I den här artikeln ska jag visa dig hur du hittar och väljer element från webbsidor med XPath-väljare i Selen med Selenium python-biblioteket. Så, låt oss komma igång.
Förutsättningar:
För att prova kommandon och exempel på den här artikeln måste du ha,
- En Linux-distribution (helst Ubuntu) installerad på din dator.
- Python 3 installerad på din dator.
- PIP 3 installerad på din dator.
- Pytonorm virtualenv paketet installerat på din dator.
- Mozilla Firefox eller Google Chrome webbläsare installerade på din dator.
- Måste veta hur man installerar Firefox Gecko Driver eller Chrome Web Driver.
För att uppfylla kraven 4, 5 och 6, läs min artikel Introduktion till selen i Python 3. Du kan hitta många artiklar om de andra ämnena på LinuxHint.com. Var noga med att kolla in dem om du behöver hjälp.
Ställa in en projektkatalog:
Skapa en ny projektkatalog för att hålla allt ordnat selen-xpath / som följer:
$ mkdir -pv selen-xpath / drivrutiner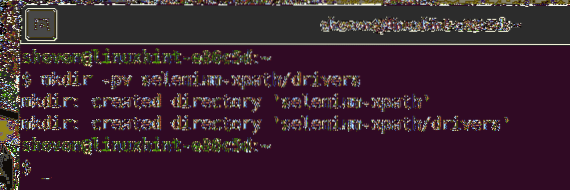
Navigera till selen-xpath / projektkatalog enligt följande:
$ cd selen-xpath /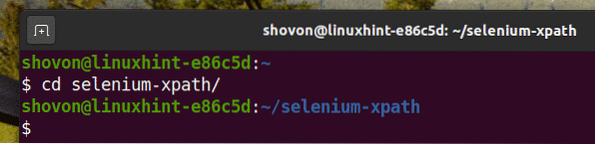
Skapa en virtuell Python-miljö i projektkatalogen enligt följande:
$ virtualenv .venv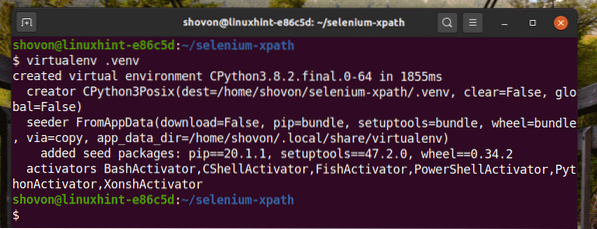
Aktivera den virtuella miljön enligt följande:
$ källa .venv / bin / aktivera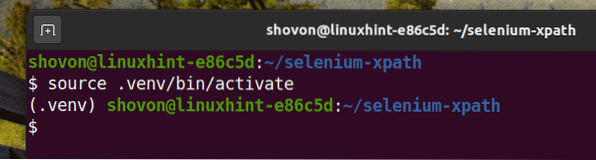
Installera Selenium Python-biblioteket med PIP3 enligt följande:
$ pip3 installera selen
Ladda ner och installera alla nödvändiga webbdrivrutiner i förare / projektkatalogen. Jag har förklarat processen för nedladdning och installation av webbdrivrutiner i min artikel Introduktion till selen i Python 3.
Skaffa XPath Selector med Chrome Developer Tool:
I det här avsnittet ska jag visa dig hur du hittar XPath-väljaren för det webbsidaelement du vill välja med Selen med det inbyggda utvecklarverktyget i webbläsaren Google Chrome.
För att få XPath-väljaren med Google Chrome-webbläsaren, öppna Google Chrome och besök webbplatsen som du vill extrahera data från. Tryck sedan på höger musknapp (RMB) på ett tomt område på sidan och klicka på Inspektera för att öppna Chrome Developer Tool.
Du kan också trycka på
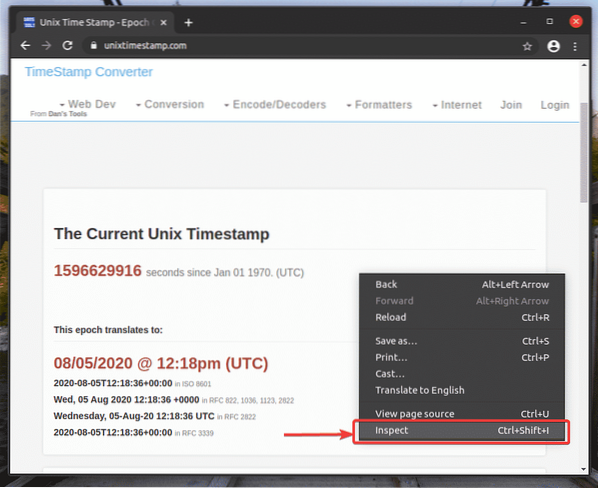
Chrome Developer Tool bör öppnas.
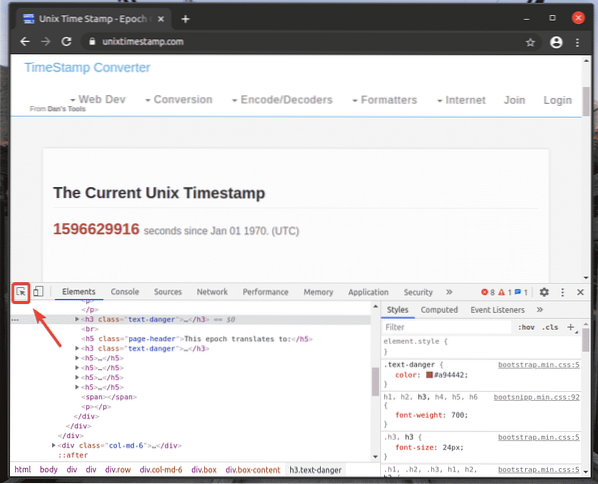
För att hitta HTML-representationen för önskat webbsidealement, klicka på Inspektera(
) -ikonen, som markeras i skärmdumpen nedan.
Håll sedan muspekaren över önskat webbsidelement och tryck på vänster musknapp (LMB) för att välja den.
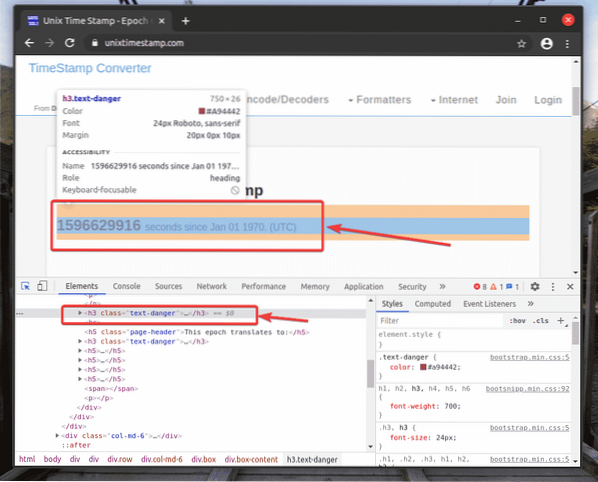
HTML-representationen för det webbelement du har valt kommer att markeras i Element fliken i Chrome Developer Tool, som du kan se på skärmdumpen nedan.
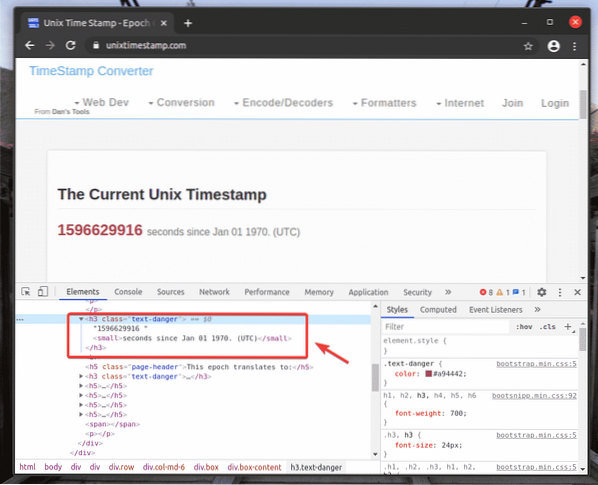
För att hämta XPath-väljaren för ditt önskade element, välj elementet från Element flik för Chrome Developer Tool och högerklicka (RMB) på den. Välj sedan Kopiera > Kopiera XPath, som markerat i skärmdumpen nedan.
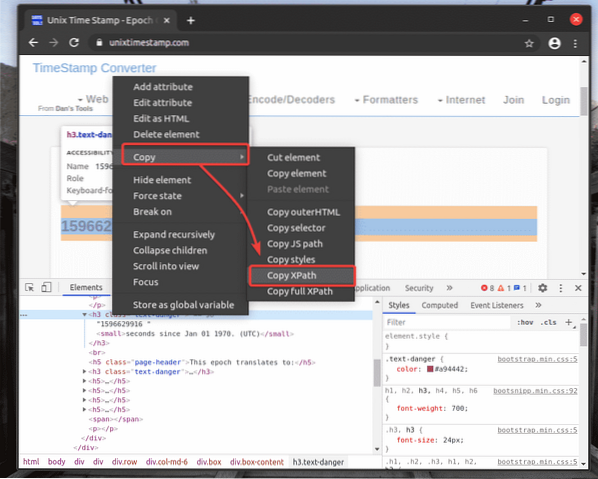
Jag har klistrat in XPath-väljaren i en textredigerare. XPath-väljaren ser ut som på skärmdumpen nedan.

Skaffa XPath Selector med Firefox Developer Tool:
I det här avsnittet ska jag visa dig hur du hittar XPath-väljaren för det webbsidaelement du vill välja med Selen med det inbyggda utvecklarverktyget i webbläsaren Mozilla Firefox.
För att få XPath-väljaren med Firefox-webbläsaren, öppna Firefox och besök webbplatsen som du vill extrahera data från. Tryck sedan på höger musknapp (RMB) på ett tomt område på sidan och klicka på Inspektera element (Q) för att öppna Firefox Developer Tool.
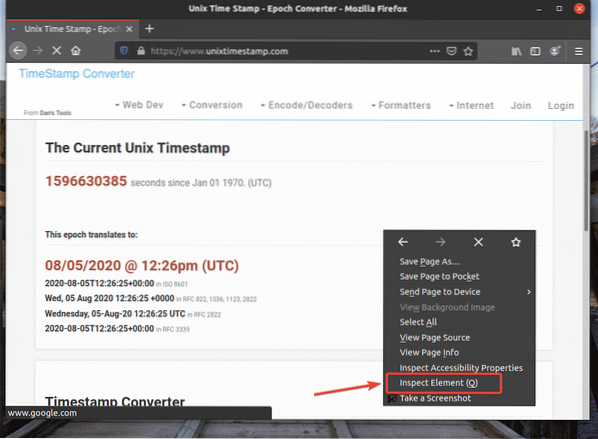
Firefox Developer Tool bör öppnas.
För att hitta HTML-representationen för önskat webbsidealement, klicka på Inspektera(
) -ikonen, som markeras i skärmdumpen nedan.
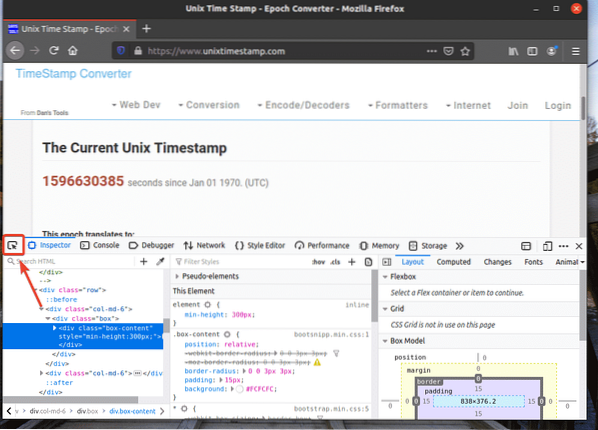
Håll sedan muspekaren över önskat webbsidelement och tryck på vänster musknapp (LMB) för att välja det.
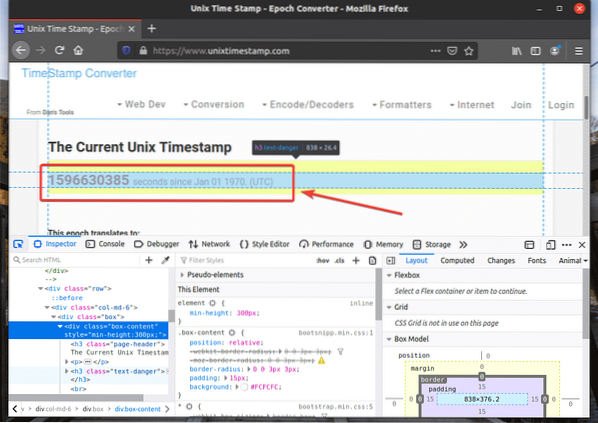
HTML-representationen för det webbelement du har valt kommer att markeras i Inspektör flik för Firefox Developer Tool, som du kan se på skärmdumpen nedan.
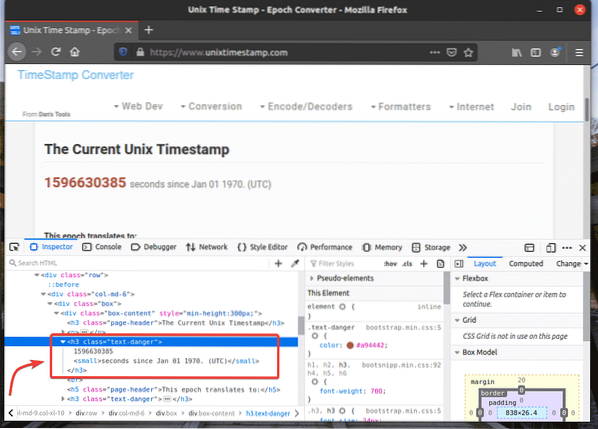
För att hämta XPath-väljaren för ditt önskade element, välj elementet från Inspektör flik för Firefox Developer Tool och högerklicka (RMB) på den. Välj sedan Kopiera > XPath som markerat i skärmdumpen nedan.
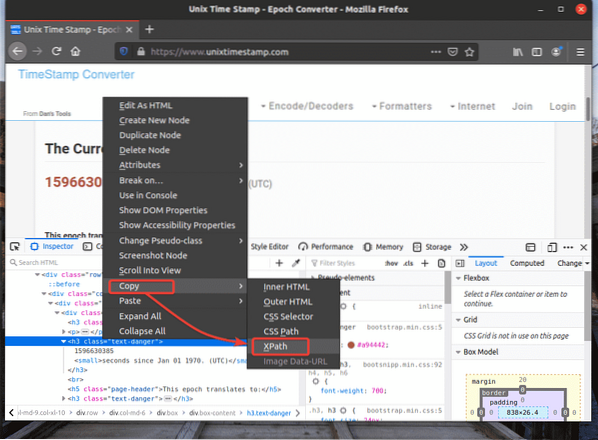
XPath-väljaren för ditt önskade element ska se ut så här.

Extrahera data från webbsidor med XPath Selector:
I det här avsnittet ska jag visa dig hur du väljer webbsidelement och extraherar data från dem med XPath-väljare med Selenium Python-biblioteket.
Skapa först ett nytt Python-skript ex01.py och skriv in följande rader med koder.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
från selen.webbdrivare.allmänning.genom import av
alternativ = webdriver.ChromeOptions ()
alternativ.headless = Sant
webbläsare = webdriver.Chrome (executable_path = "./ drivrutiner / kromförare ",
alternativ = alternativ)
webbläsare.få ("https: // www.unixtimestamp.com / ")
tidsstämpel = webbläsare.find_element_by_xpath ('/ html / body / div [1] / div [1]
/ div [2] / div [1] / div / div / h3 [2] ')
skriv ut ('Aktuell tidsstämpel:% s'% (tidsstämpel.text.split (") [0]))
webbläsare.stänga()
När du är klar sparar du ex01.py Python-skript.
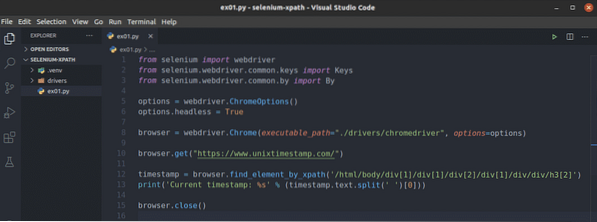
Linje 1-3 importerar alla nödvändiga Selen-komponenter.

Rad 5 skapar ett Chrome-alternativobjekt och rad 6 aktiverar headless-läge för Chrome-webbläsaren.

Linje 8 skapar en Chrome webbläsare objekt med hjälp av kromförare binär från förare / projektkatalogen.

Rad 10 ber webbläsaren att ladda webbplatsen unixtimestamp.com.

Rad 12 hittar elementet som har tidsstämpeldata från sidan med XPath-väljaren och lagrar den i tidsstämpel variabel.
Rad 13 analyserar tidsstämpeldata från elementet och skriver ut det på konsolen.

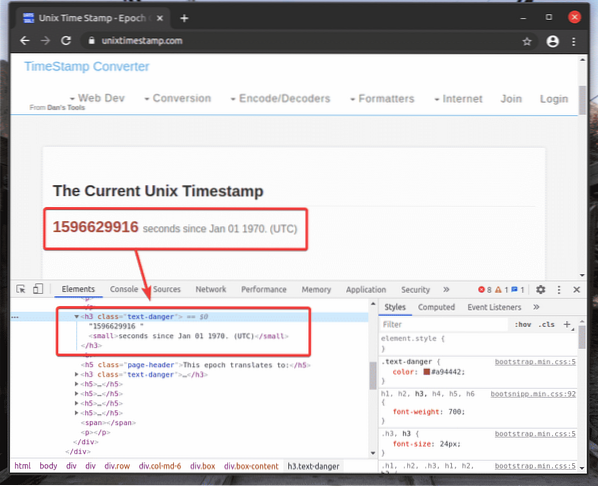
Jag har kopierat XPath-väljaren till det markerade h2 element från unixtimestamp.com med hjälp av Chrome Developer Tool.
Rad 14 stänger webbläsaren.

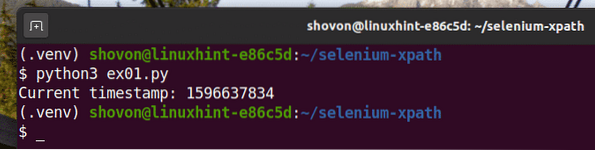
Kör Python-skriptet ex01.py som följer:
$ python3 ex01.py
Som du kan se, skrivs tidsstämpeldata ut på skärmen.
Här har jag använt webbläsare.find_element_by_xpath (väljare) metod. Den enda parametern för denna metod är väljare, vilket är XPath-väljaren för elementet.
Istället för webbläsare.hitta_element_by_xpath () metod kan du också använda webbläsare.hitta_element (av, väljare) metod. Denna metod behöver två parametrar. Den första parametern Förbi kommer vara Förbi.XPATH eftersom vi kommer att använda XPath-väljaren och den andra parametern väljare kommer att vara XPath-väljaren själv. Resultatet blir detsamma.
För att se hur webbläsare.hitta_element () metoden fungerar för XPath-väljaren, skapa ett nytt Python-skript ex02.py, kopiera och klistra in alla rader från ex01.py till ex02.py och förändring rad 12 som markerat i skärmdumpen nedan.
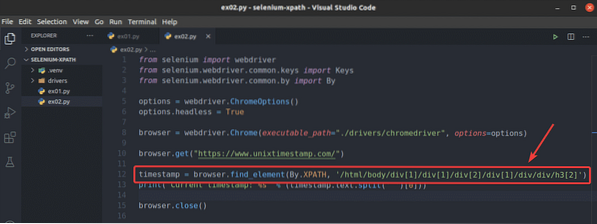
Som du kan se, Python-skriptet ex02.py ger samma resultat som ex01.py.
$ python3 ex02.py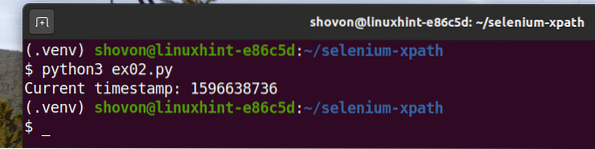
De webbläsare.hitta_element_by_xpath () och webbläsare.hitta_element () metoder används för att hitta och välja ett enda element från webbsidor. Om du vill hitta och välja flera element med XPath-väljare måste du använda webbläsare.find_elements_by_xpath () eller webbläsare.hitta_element () metoder.
De webbläsare.find_elements_by_xpath () metoden tar samma argument som webbläsare.hitta_element_by_xpath () metod.
De webbläsare.hitta_element () metoden tar samma argument som webbläsare.hitta_element () metod.
Låt oss se ett exempel på att extrahera en lista med namn med XPath-väljaren från slumpmässiga namn-generator.info med Selenium Python-biblioteket.
Den oordnade listan (ol tag) har en 10 li taggar inuti som innehåller ett slumpmässigt namn. XPath för att välja alla li taggar inuti ol tag i detta fall är // * [@ id = ”main”] / div [3] / div [2] / ol // li
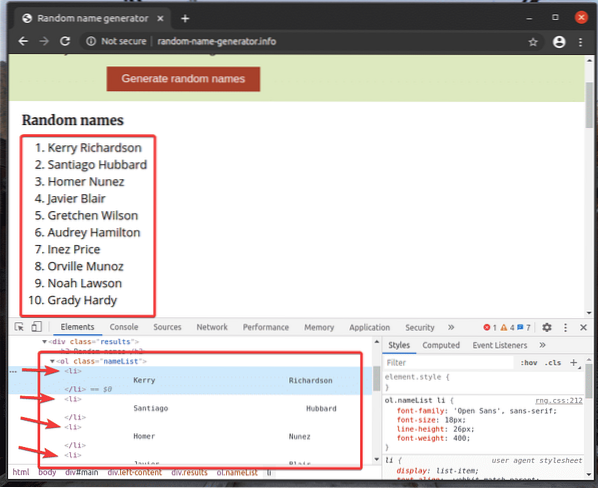
Låt oss gå igenom ett exempel på att välja flera element från webbsidan med XPath-väljare.
Skapa ett nytt Python-skript ex03.py och skriv in följande rader med koder i den.
från selenimportwebdriverfrån selen.webbdrivare.allmänning.nycklar importerar nycklar
från selen.webbdrivare.allmänning.genom import av
alternativ = webdriver.ChromeOptions ()
alternativ.headless = Sant
webbläsare = webdriver.Chrome (executable_path = "./ drivrutiner / kromförare ",
alternativ = alternativ)
webbläsare.get ("http: // random-name-generator.info/")
namn = webbläsare.find_elements_by_xpath ('
// * [@ id = "main"] / div [3] / div [2] / ol // li ')
för namn i namn:
Skriv namn.text)
webbläsare.stänga()
När du är klar sparar du ex03.py Python-skript.
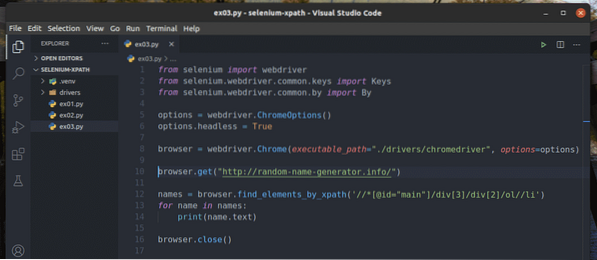
Rad 1-8 är densamma som i ex01.py Python-skript. Så jag kommer inte att förklara dem här igen.
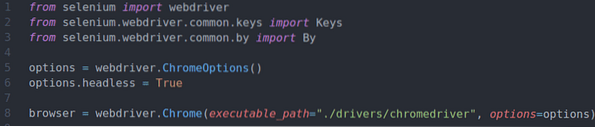
Rad 10 ber webbläsaren att ladda webbplatsens slumpmässiga namngenerator.info.

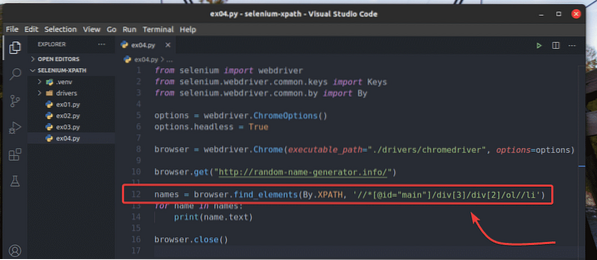
Rad 12 väljer namnlistan med webbläsare.find_elements_by_xpath () metod. Denna metod använder XPath-väljaren // * [@ id = ”main”] / div [3] / div [2] / ol // li för att hitta namnlistan. Sedan sparas namnlistan i namn variabel.

I rad 13 och 14, a för loop används för att iterera genom namn lista och skriva ut namnen på konsolen.
Rad 16 stänger webbläsaren.

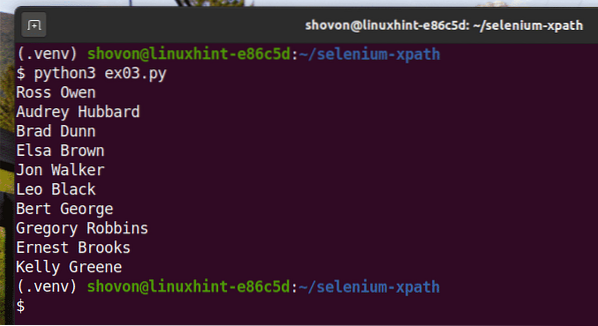
Kör Python-skriptet ex03.py som följer:
$ python3 ex03.py
Som du kan se extraheras namnen från webbsidan och skrivs ut på konsolen.
Istället för att använda webbläsare.find_elements_by_xpath () metod kan du också använda webbläsare.hitta_element () metod som tidigare. Det första argumentet för denna metod är Förbi.XPATH, och det andra argumentet är XPath-väljaren.
Att experimentera med webbläsare.hitta_element () metod, skapa ett nytt Python-skript ex04.py, kopiera alla koder från ex03.py till ex04.py, och ändra rad 12 som markerad i skärmdumpen nedan.
Du borde få samma resultat som tidigare.
$ python3 ex04.py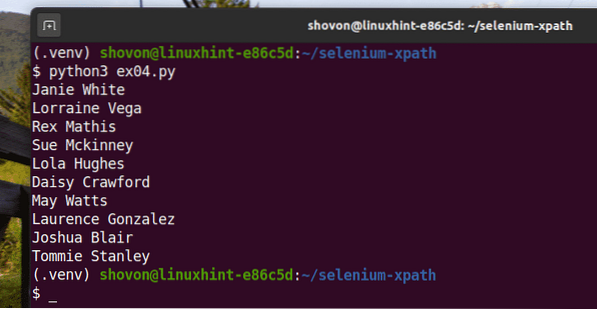
Grunderna i XPath Selector:
Utvecklarverktyget i Firefox eller webbläsaren Google Chrome genererar XPath-väljaren automatiskt. Men dessa XPath-väljare räcker ibland inte för ditt projekt. I så fall måste du veta vad en viss XPath-väljare gör för att bygga din XPath-väljare. I det här avsnittet ska jag visa dig grunderna för XPath-väljare. Då ska du kunna bygga din egen XPath-väljare.
Skapa en ny katalog www / i din projektkatalog enligt följande:
$ mkdir -v www
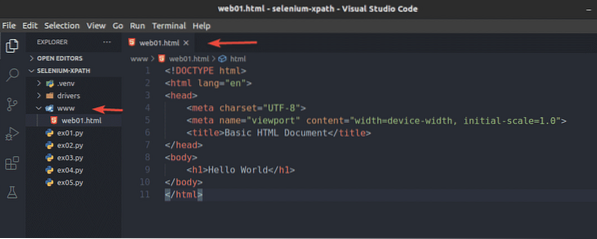
Skapa en ny fil web01.html i www / katalog och skriv in följande rader i den filen.
Hej världen
När du är klar sparar du web01.html fil.
Kör en enkel HTTP-server på port 8080 med följande kommando:
$ python3 -m http.server - katalog www / 8080
HTTP-servern ska starta.
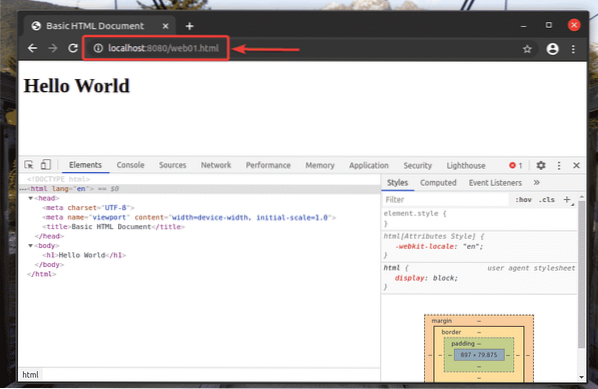
Du bör kunna komma åt webb01.html fil med webbadressen http: // localhost: 8080 / web01.html, som du kan se på skärmdumpen nedan.
Medan Firefox eller Chrome Developer Tool öppnas trycker du på
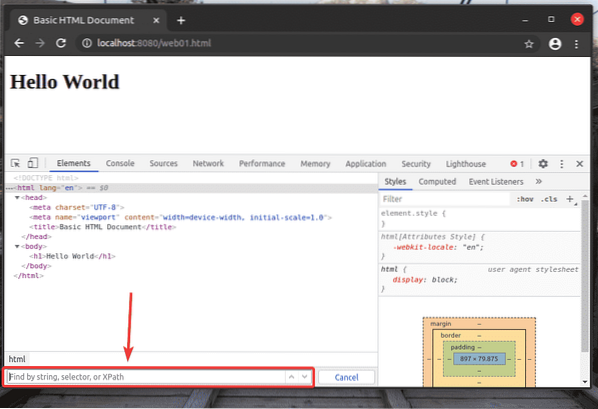
En XPath-väljare börjar med en snedstreck (/) för det mesta. Det är som ett Linux-katalogträd. De / är roten till alla element på webbsidan.
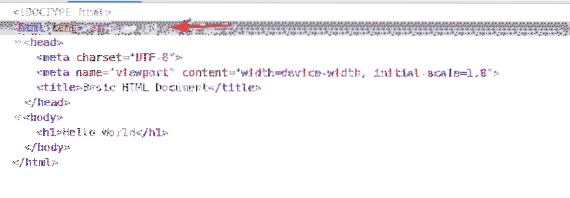
Det första elementet är html. Så XPath-väljaren / html väljer hela html märka.
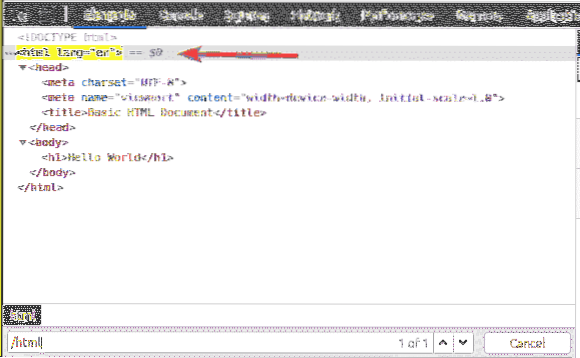
Inuti html tag, vi har en kropp märka. De kropp taggen kan väljas med XPath-väljaren / html / body
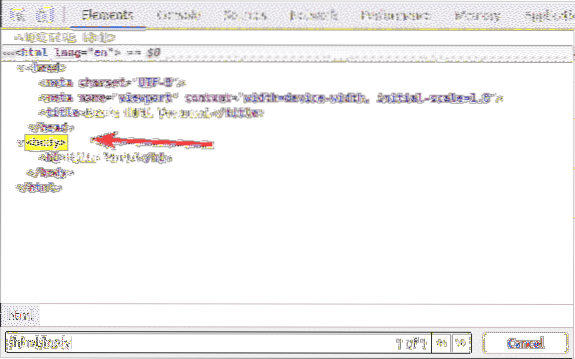
De h1 sidhuvudet är inne i kropp märka. De h1 rubrik kan väljas med XPath-väljaren / html / body / h1
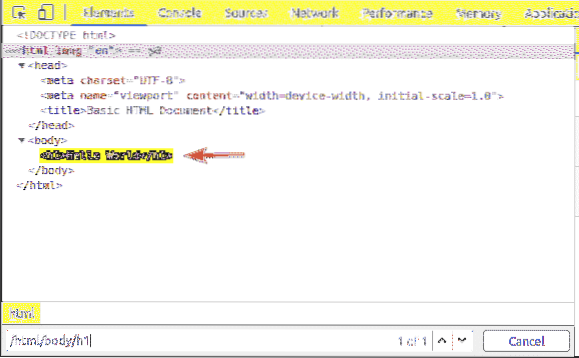
Denna typ av XPath-väljare kallas en absolut sökväg. I absolut sökväg måste du korsa webbsidan från sidens rot (/). Nackdelen med en absolut sökväg är att även en liten förändring av webbsidans struktur kan göra din XPath-väljare ogiltig. Lösningen på detta problem är en relativ eller partiell XPath-väljare.
Skapa en ny fil för att se hur relativ sökväg eller partiell sökväg fungerar web02.html i www / katalog och skriv in följande rader med koder i den.
Hej världen
detta är meddelande
Hej världen
När du är klar sparar du web02.html filen och ladda den i din webbläsare.
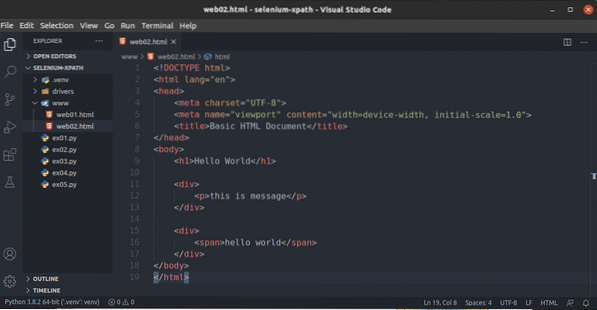
Som du kan se, XPath-väljaren // div / p väljer sid tagg inuti div märka. Detta är ett exempel på en relativ XPath-väljare.
Relativ XPath-väljare börjar med //. Sedan anger du strukturen för det element du vill välja. I detta fall, div / s.
Så, // div / p betyder välj sid element inuti en div element, spelar ingen roll vad som kommer före det.
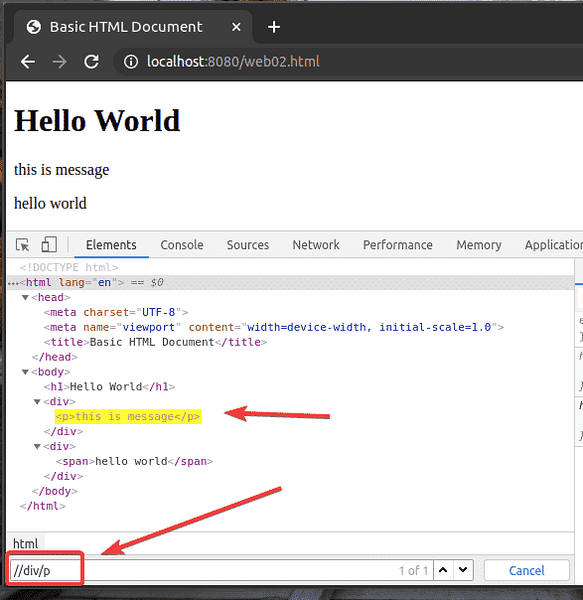
Du kan också välja element efter olika attribut som id, klass, typ, etc. med XPath-väljaren. Låt oss se hur man gör det.
Skapa en ny fil web03.html i www / katalog och skriv in följande rader med koder i den.
Hej världen
detta är ett meddelande
detta är ett annat meddelande
rubrik 2
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Quibusdam
eligendi doloribus sapiente, molestias quos quae non nam incidunt quis delectus
facilis magni officiis alias neque atque fuga? Unde, aut natus?
När du är klar sparar du web03.html filen och ladda den i din webbläsare.
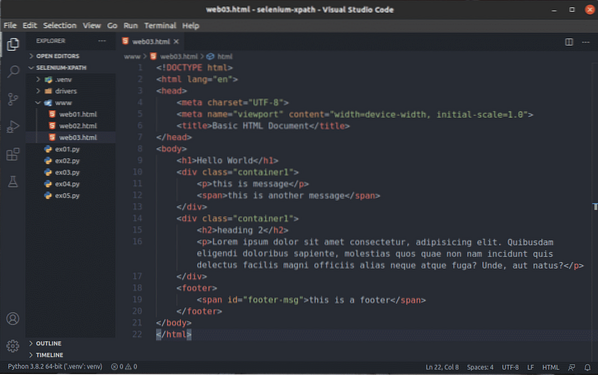
Låt oss säga att du vill välja alla div element som har klass namn behållare1. För att göra det kan du använda XPath-väljaren // div [@ class = 'container1']
Som du kan se har jag två element som matchar XPath-väljaren // div [@ class = 'container1']
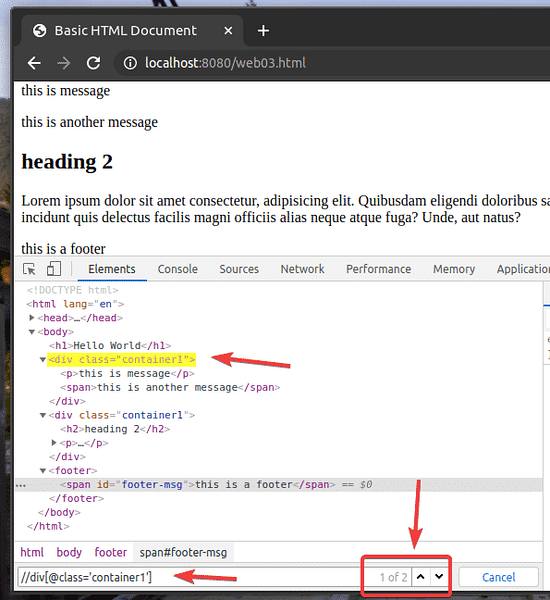
För att välja den första div element med klass namn behållare1, Lägg till [1] i slutet av XPath välj, som visas på skärmdumpen nedan.
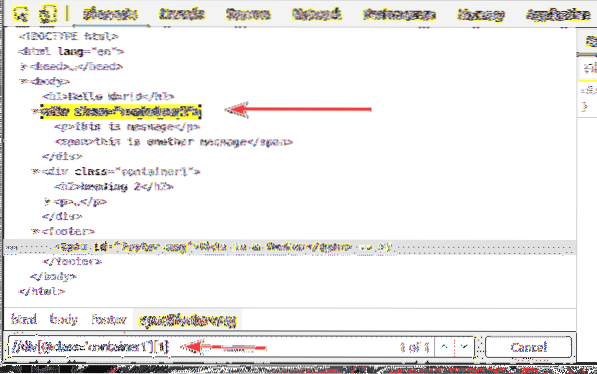
På samma sätt kan du välja den andra div element med klass namn behållare1 med XPath-väljaren // div [@ class = 'container1'] [2]
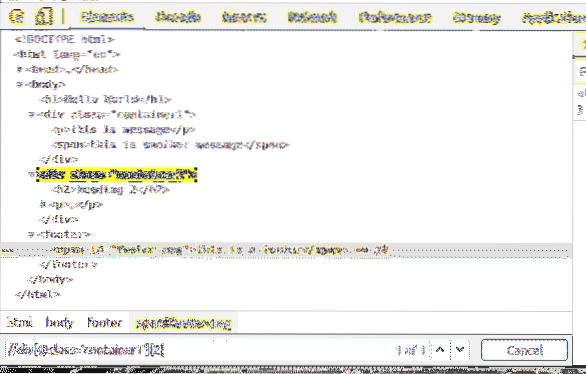
Du kan välja element efter id också.
Till exempel för att välja det element som har id av sidfot-msg, du kan använda XPath-väljaren // * [@ id = 'footer-msg']
Här, den * innan [@ id = 'footer-msg'] används för att välja vilket element som helst oavsett deras tagg.
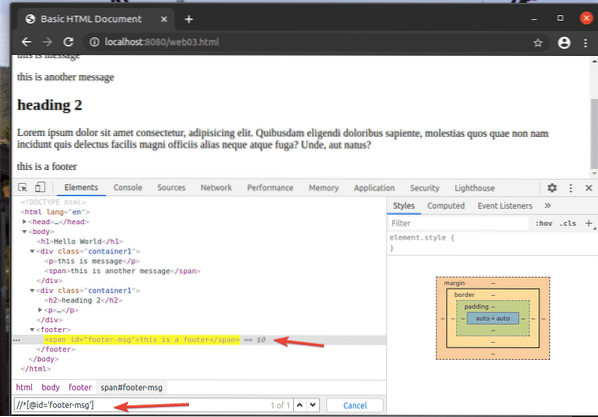
Det är grunderna i XPath-väljaren. Nu ska du kunna skapa din egen XPath-väljare för dina Selen-projekt.
Slutsats:
I den här artikeln har jag visat dig hur du hittar och väljer element från webbsidor med hjälp av XPath-väljaren med Selenium Python-biblioteket. Jag har också diskuterat de vanligaste XPath-väljarna. Efter att ha läst den här artikeln bör du känna dig ganska säker på att välja element från webbsidor med XPath-väljaren med Selenium Python-biblioteket.


