Antag att du är ägare till en stor försörjningsbutik i det län där du bor. Antag att du bor i ett stort område, som inte är ett kommersiellt område. Du är inte den enda med en försörjningsbutik i området; du har några konkurrenter. Och då tänker det på dig att du ska registrera dina kunders telefonnummer i en träningsbok. Naturligtvis är övningsboken liten och du kan inte spela in alla telefonnummer för alla dina kunder.
Så du bestämmer dig för att bara spela in telefonnummer till dina vanliga kunder. Och så har du en tabell med två kolumner. Kolumnen till vänster har namnen på kunder och kolumnen till höger har motsvarande telefonnummer. På detta sätt finns det en kartläggning mellan kundnamn och telefonnummer. Den högra kolumnen i tabellen kan betraktas som kärnhashtabellen. Kundnamn kallas nu nycklar och telefonnummer kallas värden. Observera att när en kund går på överföring måste du avbryta sin rad, så att raden är tom eller ersättas med en ny vanlig kunds. Observera också att med tiden kan antalet vanliga kunder öka eller minska, så bordet kan växa eller krympa.
Som ett annat exempel på kartläggning, antar att det finns en klubb av jordbrukare i ett län. Naturligtvis kommer inte alla bönder att vara medlemmar i klubben. Vissa medlemmar i klubben kommer inte att vara vanliga medlemmar (närvaro och bidrag). Bar-mannen kan besluta att registrera namnen på medlemmarna och deras val av dryck. Han utvecklar en tabell med två kolumner. I den vänstra kolumnen skriver han namnen på klubbmedlemmarna. I den högra kolumnen skriver han motsvarande val av dryck.
Det finns ett problem här: det finns dubbletter i den högra kolumnen. Det vill säga samma namn på en drink finns mer än en gång. Med andra ord, olika medlemmar dricker samma söta dryck eller samma alkoholhaltiga dryck, medan andra medlemmar dricker en annan söt eller alkoholhaltig dryck. Bar-man bestämmer sig för att lösa detta problem genom att infoga en smal kolumn mellan de två kolumnerna. I den här mellersta kolumnen, från början, numrerar han raderna som börjar från noll (i.e. 0, 1, 2, 3, 4, etc.), går ner, ett index per rad. Med detta löses hans problem, eftersom ett medlemsnamn nu kartläggs till ett index och inte till namnet på en drink. Så när en drink identifieras med ett index mappas ett kundnamn till motsvarande index.
Enbart kolumnen med värden (drycker) utgör den grundläggande hashtabellen. I den modifierade tabellen bildar kolumnen med index och deras tillhörande värden (med eller utan dubbletter) en normal hash-tabell - fullständig definition av en hash-tabell ges nedan. Nycklarna (första kolumnen) ingår inte nödvändigtvis i hashtabellen.
Som ett annat exempel igen, överväga en nätverksserver där en användare från sin klientdator kan lägga till lite information, radera information eller ändra information. Det finns många användare för servern. Varje användarnamn motsvarar ett lösenord som är lagrat på servern. De som underhåller servern kan se användarnamnen och motsvarande lösenord och på så sätt kunna skada användarnas arbete.
Så ägaren av servern bestämmer sig för att producera en funktion som krypterar ett lösenord innan det lagras. En användare loggar in på servern med sitt vanliga lösenord. Nu lagras dock varje lösenord i krypterad form. Om någon ser ett krypterat lösenord och försöker logga in med det fungerar det inte, för att logga in, får ett förstått lösenord av servern och inte ett krypterat lösenord.
I det här fallet är det förstådda lösenordet nyckeln och det krypterade lösenordet är värdet. Om det krypterade lösenordet finns i en kolumn med krypterade lösenord är kolumnen en grundläggande hashtabell. Om den kolumnen föregås av en annan kolumn med index som börjar från noll, så att varje krypterat lösenord är associerat med ett index, så bildar både kolumnen med index och den krypterade lösenordskolumnen en normal hash-tabell. Nycklarna är inte nödvändigtvis en del av hashtabellen.
Observera i det här fallet att varje nyckel, som är ett förstått lösenord, motsvarar ett användarnamn. Så det finns ett användarnamn som motsvarar en nyckel som är mappad till ett index, vilket är associerat med ett värde som är en krypterad nyckel.
Definitionen av en hash-funktion, den fullständiga definitionen av en hash-tabell, innebörden av en matris och andra detaljer ges nedan. Du måste ha kunskap om pekare (referenser) och länkade listor för att uppskatta resten av denna handledning.
Betydelse av Hash-funktion och Hash-tabell
Array
En array är en uppsättning på varandra följande minnesplatser. Alla platser är av samma storlek. Värdet på den första platsen nås med indexet 0; värdet i den andra platsen nås med indexet 1; det tredje värdet nås med indexet 2; fjärde med index, 3; och så vidare. En matris kan normalt inte öka eller krympa. För att ändra storleken (längden) på en array måste en ny array skapas och motsvarande värden kopieras till den nya arrayen. Värdena för en matris är alltid av samma typ.
Hash-funktion
I programvara är en hash-funktion en funktion som tar en nyckel och producerar ett motsvarande index för en array-cell. Matrisen har en fast storlek (fast längd). Antalet nycklar har godtycklig storlek, vanligtvis större än storleken på matrisen. Indexet som härrör från hashfunktionen kallas ett hashvärde eller en sammandragning eller en hashkod eller helt enkelt en hash.
Hash-bord
En hash-tabell är en matris med värden, till vars index, nycklar mappas. Nycklarna mappas indirekt till värdena. Faktum är att tangenterna sägs vara mappade till värdena, eftersom varje index är associerat med ett värde (med eller utan dubbletter). Men den funktion som gör kartläggning (i.e. hashing) relaterar nycklar till matrisindexen och inte riktigt till värdena, eftersom det kan finnas dubbletter i värdena. Följande diagram illustrerar en hashtabell för namnen på personer och deras telefonnummer. Arraycellerna (slots) kallas hinkar.
Observera att vissa skopor är tomma. En hash-tabell måste inte nödvändigtvis ha värden i alla sina hinkar. Värdena i skoporna får inte nödvändigtvis vara i stigande ordning. De index som de är associerade med är dock i stigande ordning. Pilarna visar kartläggningen. Observera att nycklarna inte finns i en matris. De behöver inte vara i någon struktur. En hash-funktion tar vilken tangent som helst och hasar ut ett index för en matris. Om det inte finns något värde i skopan som är associerad med index-hash, kan ett nytt värde läggas i skopan. Det logiska förhållandet är mellan nyckeln och indexet, och inte mellan nyckeln och det värde som är associerat med indexet.
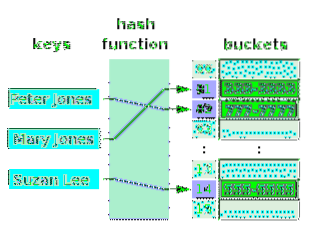
Värdena för en matris, liksom värdena i den här hashtabellen, är alltid av samma datatyp. En hash-tabell (hinkar) kan ansluta nycklar till värdena för olika datatyper. I det här fallet är matrisens värden alla pekare och pekar på olika värdetyper.
En hash-tabell är en matris med en hash-funktion. Funktionen tar en nyckel och hasar ett motsvarande index och kopplar så nycklar till värden i matrisen. Nycklarna behöver inte vara en del av hashtabellen.
Varför Array och inte länkad lista för Hash-tabell
Matrisen för en hash-tabell kan ersättas med en länkad datastruktur, men det skulle vara ett problem. Det första elementet i en länkad lista är naturligtvis i index, 0; det andra elementet är naturligtvis vid index, 1; den tredje är naturligtvis vid index, 2; och så vidare. Problemet med den länkade listan är att för att hämta ett värde måste listan iteras igenom, och det tar tid. Åtkomst till ett värde i en matris sker genom slumpmässig åtkomst. När indexet är känt erhålls värdet utan iteration; denna åtkomst är snabbare.
Kollision
Hashfunktionen tar en nyckel och haschar motsvarande index, för att läsa tillhörande värde eller för att infoga ett nytt värde. Om syftet är att läsa ett värde finns det inga problem (inga problem), hittills. Men om syftet är att infoga ett värde kan det hashade indexet redan ha ett associerat värde, och det är en kollision; det nya värdet kan inte sättas där det redan finns ett värde. Det finns sätt att lösa kollision - se nedan.
Varför kollision inträffar
I exemplet med provningsbutiken ovan är kundnamnen nycklarna och namnen på dryckerna är värdena. Lägg märke till att kunderna är för många, medan arrayen har en begränsad storlek och inte kan ta alla kunder. Så, endast drycker från vanliga kunder lagras i matrisen. Kollisionen skulle inträffa när en icke-vanlig kund blir vanlig. Kunderna till butiken bildar en stor uppsättning, medan antalet skopor för kunder i matrisen är begränsat.
Med hashtabeller är det värdena för tangenterna som är mycket troliga som registreras. När en nyckel som inte var sannolik blir sannolik skulle det troligen bli en kollision. Faktum är att kollision alltid sker med hashtabeller.
Grunderna för kollisionsupplösning
Två tillvägagångssätt för kollisionsupplösning kallas separat kedja och öppen adressering. I teorin bör nycklarna inte vara i datastrukturen eller inte vara en del av hashtabellen. Båda metoderna kräver dock att nyckelkolumnen föregår hashtabellen och blir en del av den övergripande strukturen. Istället för att nycklar finns i nyckelkolumnen kan pekare till tangenterna finnas i nyckelkolumnen.
En praktisk hash-tabell innehåller en nyckelkolumn, men den här nyckelkolumnen är inte officiellt en del av hash-tabellen.
Endera metoden för upplösning kan ha tomma hinkar, inte nödvändigtvis i slutet av matrisen.
Separat kedja
I en separat kedja läggs det nya värdet till höger (inte över eller under) om det kolliderade värdet när en kollision inträffar. Så två eller tre värden får samma index. Sällan mer än tre bör ha samma index.
Kan mer än ett värde verkligen ha samma index i en matris? - Nej. Så i många fall är det första värdet för indexet en pekare till en länkad datastruktur, som innehåller en, två eller tre kolliderade värden. Följande diagram är ett exempel på en hashtabell för separat kedjning av kunder och deras telefonnummer:
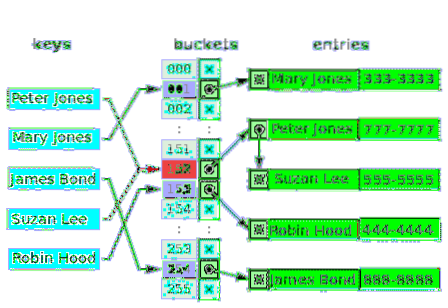
De tomma skoporna är markerade med bokstaven x. Resten av slots har pekare till länkade listor. Varje element i den länkade listan har två datafält: ett för kundnamnet och det andra för telefonnumret. Konflikt uppstår för nycklarna: Peter Jones och Suzan Lee. Motsvarande värden består av två element i en länkad lista.
För motstridiga nycklar är kriteriet för att infoga värde samma kriterium som används för att lokalisera (och läsa) värdet.
Öppna adressering
Med öppen adressering lagras alla värden i skopmatrisen. När konflikt inträffar infogas det nya värdet i en tom hink ny motsvarande värde för konflikten, enligt något kriterium. Kriteriet som används för att infoga ett värde i konflikt är samma kriterium som används för att lokalisera (söka och läsa) värdet.
Följande diagram illustrerar konfliktlösning med öppen adressering:
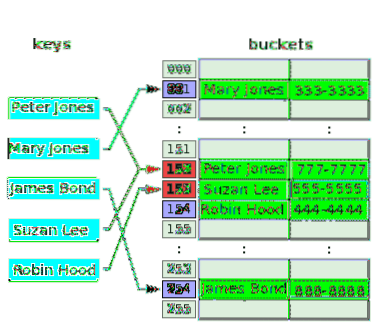 Hashfunktionen tar nyckeln, Peter Jones och hasar indexet, 152, och lagrar sitt telefonnummer vid tillhörande hink. Efter en tid hasar hashfunktionen samma index, 152 från nyckeln, Suzan Lee, kolliderar med indexet för Peter Jones. För att lösa detta lagras värdet för Suzan Lee i skopan i nästa index, 153, som var tomt. Hashfunktionen hasar indexet, 153 för nyckeln, Robin Hood, men detta index har redan använts för att lösa konflikten för en tidigare nyckel. Så värdet för Robin Hood placeras i nästa tomma hink, det vill säga index 154.
Hashfunktionen tar nyckeln, Peter Jones och hasar indexet, 152, och lagrar sitt telefonnummer vid tillhörande hink. Efter en tid hasar hashfunktionen samma index, 152 från nyckeln, Suzan Lee, kolliderar med indexet för Peter Jones. För att lösa detta lagras värdet för Suzan Lee i skopan i nästa index, 153, som var tomt. Hashfunktionen hasar indexet, 153 för nyckeln, Robin Hood, men detta index har redan använts för att lösa konflikten för en tidigare nyckel. Så värdet för Robin Hood placeras i nästa tomma hink, det vill säga index 154.
Metoder för att lösa konflikter för separat kedjning och öppen adressering
Separat kedja har sina metoder för att lösa konflikter, och öppen adressering har också sina egna metoder för att lösa konflikter.
Metoder för att lösa separata kedjekonflikter
Metoderna för separata hashtabeller för kedjor förklaras kort nu:
Separat kedja med länkade listor
Denna metod är som förklarats ovan. Varje element i den länkade listan måste dock inte nödvändigtvis ha nyckelfältet (e.g. kundnamnsfält ovan).
Separat kedja med listhuvudceller
I den här metoden lagras det första elementet i den länkade listan i en grupp i matrisen. Detta är möjligt, om datatypen för matrisen, är elementet i den länkade listan.
Separat kedja med andra strukturer
Alla andra datastrukturer, till exempel det självbalanserande binära sökträdet som stöder de nödvändiga operationerna, kan användas istället för den länkade listan - se senare.
Metoder för att lösa öppna adresseringskonflikter
En metod för att lösa konflikter i öppen adressering kallas sondföljd. Tre välkända probsekvenser förklaras kort nu:
Linjär sondering
Med linjär sondering letas efter när en konflikt inträffar närmaste tomma hink under hinken vid konflikt. Vid linjär sondering lagras både nyckeln och dess värde i samma hink.
Kvadratisk sondering
Antag att konflikt uppstår i index H. Nästa tomma lucka (hink) vid index H + 12 är använd; om det redan är upptaget, så är det nästa tomma vid H + 22 används, om det redan är upptaget, så är nästa tomma vid H + 32 används och så vidare. Det finns varianter av detta.
Dubbel hasning
Med dubbel hasning finns det två hashfunktioner. Den första beräknar (hasar) indexet. Om en konflikt uppstår använder den andra samma tangent för att bestämma hur långt ner värdet ska infogas. Det finns mer till detta - se senare.
Perfekt Hash-funktion
En perfekt hashfunktion är en hashfunktion som inte kan resultera i någon kollision. Detta kan hända när nyckeluppsättningen är relativt liten och varje tangent mappas till ett visst heltal i hashtabellen.
I ASCII-teckenuppsättning kan stora bokstäver mappas till motsvarande gemener med en hash-funktion. Bokstäver representeras i datorminnet som siffror. I ASCII-teckenuppsättning är A 65, B är 66, C är 67, etc. och a är 97, b är 98, c är 99, etc. För att kartlägga från A till a, lägg till 32 till 65; för att kartlägga från B till b, lägg till 32 till 66; för att kartlägga från C till c, lägg till 32 till 67; och så vidare. Här är stora bokstäver tangenterna och små bokstäver är värdena. Hashtabellen för detta kan vara en matris vars värden är tillhörande index. Kom ihåg att hinkar i matrisen kan vara tomma. Så hinkar i matrisen från 64 till 0 kan vara tomma. Hashfunktionen lägger helt enkelt till 32 i versalens kodnummer för att få indexet, och därav gemener. En sådan funktion är en perfekt hashfunktion.
Hashing från heltal till heltalindex
Det finns olika metoder för att haska heltal. En av dem kallas Modulo Division Method (Function).
Modulo Division Hashing-funktionen
En funktion i datorprogramvara är inte en matematisk funktion. I databehandling (programvara) består en funktion av en uppsättning uttalanden som föregås av argument. För Modulo Division-funktionen är tangenterna heltal och mappas till index för matrisen. Uppsättningen av nycklar är stor, så endast nycklar som är mycket troliga att inträffa i aktiviteten kan kartläggas. Så kollisioner inträffar när osannolika nycklar måste mappas.
I uttalandet,
20/6 = 3R2
20 är utdelningen, 6 är delaren och 3 resten 2 är kvoten. Resten 2 kallas också modulo. Obs: det är möjligt att ha en modulo 0.
För denna hashing är bordets storlek vanligtvis en effekt på 2, e.g. 64 = 26 eller 256 = 28, etc. Delaren för denna hashfunktion är ett primtal nära matrisstorleken. Denna funktion delar nyckeln med delaren och returnerar modulo. Modulen är indexet för uppsättningen skopor. Det tillhörande värdet i skopan är ett värde du väljer (värde för nyckeln).
Hashing-knappar med variabel längd
Här är nycklarna till nyckeluppsättningen texter av olika längd. Olika heltal kan lagras i minnet med samma antal byte (storleken på ett engelskt tecken är en byte). När olika tangenter har olika bytestorlek sägs de ha varierande längd. En av metoderna för hashing med variabla längder kallas Radix Conversion Hashing.
Radix Conversion Hashing
I en sträng är varje tecken i datorn ett nummer. I denna metod,
Hash-kod (index) = x0ak − 1+x1ak − 2+... + xk − 2a1+xk − 1a0
Där (x0, x1, ..., xk − 1) är inmatningssträngens tecken och a är en radix, e.g. 29 (se senare). k är antalet tecken i strängen. Det finns mer till detta - se senare.
Nycklar och värden
I ett nyckel / värdepar kan ett värde inte nödvändigtvis vara ett tal eller en text. Det kan också vara en post. En post är en lista som skrivs horisontellt. I ett nyckel / värdepar kan varje nyckel faktiskt hänvisa till någon annan text eller nummer eller post.
Associativ matris
En lista är en datastruktur, där listobjekten är relaterade, och det finns en uppsättning funktioner som fungerar på listan. Varje listobjekt kan bestå av ett par objekt. Den allmänna hashtabellen med dess nycklar kan betraktas som en datastruktur, men det är mer ett system än en datastruktur. Tangenterna och deras motsvarande värden är inte särskilt beroende av varandra. De är inte särskilt besläktade med varandra.
Å andra sidan är en associativ array en liknande sak, men nycklar och deras värden är mycket beroende av varandra; de är mycket släkt med varandra. Du kan till exempel ha en associerande mängd frukter och deras färger. Varje frukt har naturligt sin färg. Fruktens namn är nyckeln; färgen är värdet. Under införandet infogas varje nyckel med sitt värde. När du tar bort raderas varje tangent med sitt värde.
En associerande matris är en hashtabelldatastruktur bestående av nyckel / värdepar, där det inte finns någon duplikat för nycklarna. Värdena kan ha dubbletter. I denna situation är nycklarna en del av strukturen. Det vill säga tangenterna måste lagras, medan tangenterna inte behöver lagras med den allmänna tabellen. Problemet med de duplicerade värdena löses naturligtvis av indexen för matrisen. Blanda inte mellan duplicerade värden och kollision i ett index.
Eftersom en associerande matris är en datastruktur har åtminstone följande operationer:
Associative Array Operations
infoga eller lägga till
Detta infogar ett nytt nyckel / värdepar i samlingen och mappar nyckeln till dess värde.
omfördela
Den här åtgärden ersätter värdet på en viss nyckel till ett nytt värde.
ta bort eller ta bort
Detta tar bort en nyckel plus dess motsvarande värde.
slå upp
Den här åtgärden söker efter värdet på en viss nyckel och returnerar värdet (utan att ta bort det).
Slutsats
En datastruktur för hashtabell består av en matris och en funktion. Funktionen kallas en hash-funktion. Funktionen mappar nycklar till värden i matrisen genom matrisens index. Nycklarna måste inte nödvändigtvis vara en del av datastrukturen. Nyckeluppsättningen är vanligtvis större än de lagrade värdena. När en kollision inträffar löses den antingen genom den separata kedjemetoden eller den öppna adresseringsmetoden. En associerande matris är ett speciellt fall av hashtabellens datastruktur.


