Jag har använt CentOS 8 för demonstrationsändamål.
Ta bort tomma rader med kommandot grep
Grep är ett av de mest kraftfulla och mångsidiga verktygen som kan hjälpa dig att ta bort de oönskade tomma raderna i dina textfiler. Vanligtvis används kommandot för att sondera strängar eller mönster av tecken i en textfil, men som du snart kommer att se kan det också hjälpa dig att bli av med oönskade tomma rader
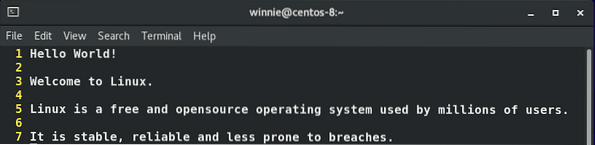
När den används med -v alternativ, grep-kommandot hjälper till att ta bort tomma rader. Nedan följer en exempeltextfil, prov.Text, med alternativa icke-tomma och tomma rader.
![]()
Om du vill ta bort eller ta bort alla tomma rader i exempeltexten använder du kommandot grep som visas.
$ grep -v '^ [[: space:]] * $' exempel.Text![]()
Dessutom kan du använda följande syntax.
$ grep -v '^ $' exempel.TextDessutom kan du spara eller omdirigera utdata på en annan fil med hjälp av till exempel större än operator (>).
$ grep -v '^ $' exempel.txt> utdata.Text![]()
Ta bort tomma rader med sed-kommandot
Förkortat som Stream-redigerare är Linux sed-kommandot ett populärt verktyg som utför en mängd funktioner inklusive ersättning och ersättning av strängar i en fil.
Dessutom kan du också använda sed för att ta bort tomma rader i en fil som visas nedan.
$ sed '/ ^ $ / d' prov.Text![]()
Ta bort tomma rader med kommandot awk
Slutligen har vi kommandot awk. Detta är ett annat kommandoradsverktyg för tet-manipulation som också kan bli av med tomma rader. För att ta bort en tom fil med awk, anropa kommandot nedan.
$ awk 'if (NF> 0) print $ 0' exempel.Text![]()
Slutsats
Vi har tillhandahållit tre sätt som kan vara användbara för att ta bort tomma rader i textfiler. Eventuella andra idéer för hur man tar bort de oönskade tomma raderna? Ta gärna kontakt med oss i kommentarsektionen.


