När vi vill integrera meddelandemäklare i vår applikation som gör det möjligt för oss att enkelt skala och ansluta vårt system på ett asynkront sätt finns det många meddelandemäklare som kan göra listan från vilken du görs att välja ett, som:
- RabbitMQ
- Apache Kafka
- ActiveMQ
- AWS SQS
- Redis
Var och en av dessa meddelandemäklare har sin egen lista över fördelar och nackdelar men de mest utmanande alternativen är de två första, RabbitMQ och Apache Kafka. I den här lektionen listar vi punkter som kan hjälpa till att begränsa beslutet att gå med varandra. Slutligen är det värt att påpeka att ingen av dessa är bättre än en annan i alla användningsfall och det beror helt på vad du vill uppnå, så det finns ingen rätt svar!
Vi börjar med en enkel introduktion av dessa verktyg.
Apache Kafka
Som vi sa i den här lektionen är Apache Kafka en distribuerad, feltolerant, horisontellt skalbar, åtagandelogg. Detta innebär att Kafka kan utföra en uppdelning och regeltermer mycket bra, det kan replikera dina data för att säkerställa tillgänglighet och är mycket skalbar i den meningen att du kan inkludera nya servrar vid körning för att öka dess kapacitet att hantera fler meddelanden.
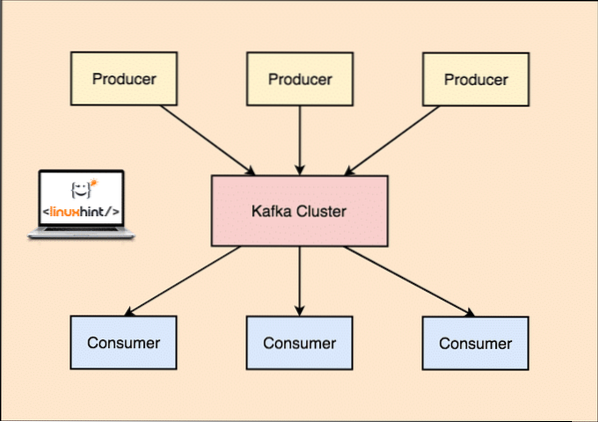
Kafka Producent och konsument
RabbitMQ
RabbitMQ är en mer allmänt ändamålsenlig och enklare att använda meddelandemäklare som i sig registrerar vilka meddelanden som konsumeras av klienten och kvarstår den andra. Även om RabbitMQ-servern av någon anledning går ner, kan du vara säker på att de meddelanden som för närvarande finns i köerna har lagrats på filsystemet så att när RabbitMQ kommer upp igen kan dessa meddelanden behandlas av konsumenterna på ett konsekvent sätt.
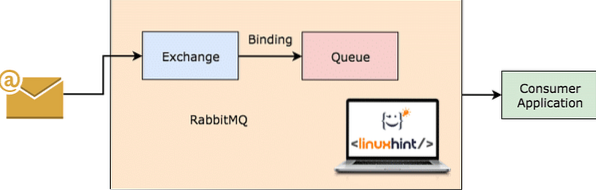
RabbitMQ arbetar
Supermakt: Apache Kafka
Kafkas största supermakt är att den kan användas som ett kösystem men det är inte det som är begränsat till. Kafka är något mer som en cirkulär buffert som kan skala så mycket som en skiva på maskinen i klustret, och därmed tillåter oss att kunna läsa igenom meddelanden. Detta kan göras av klienten utan att behöva vara beroende av Kafka-klustret eftersom det är helt kundens ansvar att notera meddelandemetadata som den läser för närvarande och det kan se Kafka senare i ett angivet intervall för att läsa samma meddelande igen.
Observera att tiden då detta meddelande kan läsas igen är begränsad och kan konfigureras i Kafka-konfiguration. Så när tiden är över finns det inget sätt som en klient kan läsa ett äldre meddelande någonsin igen.
Supermakt: RabbitMQ
RabbitMQs huvudsakliga superkraft är att den helt enkelt är skalbar, är ett högpresterande kösystem som har väldefinierade konsekvensregler och förmåga att skapa många typer av meddelandeutbytesmodeller. Det finns till exempel tre typer av utbyte som du kan skapa i RabbitMQ:
- Direktutbyte: ett till ett utbyte av ämne
- Ämnesutbyte: A ämne definieras där olika producenter kan publicera ett meddelande och olika konsumenter kan binda sig för att lyssna på det ämnet, så att var och en av dem får meddelandet som skickas till detta ämne.
- Fanout-utbyte: Detta är striktare än ämnesutbyte eftersom när ett meddelande publiceras på ett fanout-utbyte, kommer alla konsumenter som är anslutna till köer som binder sig till fanout-utbytet att ta emot meddelandet.
Har redan märkt skillnaden mellan RabbitMQ och Kafka? Skillnaden är att om en konsument inte är ansluten till ett fanout-utbyte i RabbitMQ när ett meddelande publicerades kommer det att gå förlorat eftersom andra konsumenter har konsumerat meddelandet, men detta händer inte i Apache Kafka eftersom alla konsumenter kan läsa något meddelande som de behåller sin egen markör.
RabbitMQ är mäklare-centrerad
En bra mäklare är någon som garanterar det arbete den tar på sig själv och det är vad RabbitMQ är bra på. Den lutas mot leveransgarantier mellan producenter och konsumenter, med kortvariga preferenser framför hållbara meddelanden.
RabbitMQ använder mäklaren själv för att hantera ett meddelandes tillstånd och se till att varje meddelande levereras till varje berättigad konsument.
RabbitMQ förutsätter att konsumenterna mestadels är online.
Kafka är producentcentrerat
Apache Kafka är producentcentrerad eftersom den är helt baserad kring partitionering och en ström av händelsepaket som innehåller data och omvandlar dem till hållbara meddelandemäklare med markörer som stöder batchkonsumenter som kan vara offline eller online-konsumenter som vill ha meddelanden med låg latens.
Kafka ser till att meddelandet förblir säkert fram till en viss tidsperiod genom att replikera meddelandet på dess noder i klustret och bibehålla ett konsekvent tillstånd.
Så, Kafka inte antar att någon av dess konsumenter oftast är online och inte bryr sig.
Meddelande beställning
Med RabbitMQ, ordern publicering hanteras konsekvent och konsumenter kommer att få meddelandet i själva den publicerade beställningen. På andra sidan gör Kafka inte det eftersom det antar att publicerade meddelanden är tunga så att konsumenterna är långsamma och kan skicka meddelanden i vilken ordning som helst, så att den inte hanterar ordern också. Men vi kan skapa en liknande topologi för att hantera ordern i Kafka med hjälp av konsekvent hashutbyte eller skärningsplugin., eller ännu fler typer av topologier.
Den kompletta uppgiften som hanteras av Apache Kafka är att fungera som en "stötdämpare" mellan det kontinuerliga flödet av händelser och konsumenterna som vissa är online och andra kan vara offline - bara satsvis konsumtion på timme eller till och med dagligen.
Slutsats
I den här lektionen studerade vi de stora skillnaderna (och likheter också) mellan Apache Kafka och RabbitMQ. I vissa miljöer har båda visat enastående prestanda som att RabbitMQ konsumerar miljoner meddelanden per sekund och Kafka har förbrukat flera miljoner meddelanden per sekund. Den huvudsakliga arkitektoniska skillnaden är att RabbitMQ hanterar sina meddelanden nästan i minnet och så använder ett stort kluster (30+ noder), medan Kafka faktiskt använder befogenheterna för sekventiell disk I / O-operation och kräver mindre hårdvara.
Återigen beror användningen av var och en av dem helt på användningsfallet i en applikation. Glad meddelanden !


