I den här lektionen kommer vi att se vad som är Apache Kafka och hur fungerar det tillsammans med dess vanligaste användningsfall. Apache Kafka utvecklades ursprungligen på LinkedIn 2010 och flyttade till ett Apache-projekt på toppnivå 2012. Den har tre huvudkomponenter:
- Utgivare-prenumerant: Den här komponenten ansvarar för att hantera och leverera data effektivt över Kafka-noder och konsumentapplikationer som skala mycket (som bokstavligen).
- Anslut API: Connect API är den mest användbara funktionen för Kafka och möjliggör Kafka-integration med många externa datakällor och datasänkor.
- Kafka Strömmar: Med hjälp av Kafka Streams kan vi överväga att bearbeta inkommande data i stor skala i nära realtid.
Vi kommer att studera mycket mer Kafka-koncept i kommande avsnitt. Låt oss gå vidare.
Apache Kafka-begrepp
Innan vi gräver djupare måste vi vara noggranna med några begrepp i Apache Kafka. Här är de termer som vi borde veta mycket kort:
-
- Producent: Detta är ett program som skickar meddelande till Kafka
- Konsument: Detta är ett program som konsumerar data från Kafka
- Meddelande: Data som skickas av producentansökan till konsumentansökan via Kafka
- Förbindelse: Kafka upprättar TCP-anslutning mellan Kafka-klustret och applikationerna
- Ämne: Ett ämne är en kategori till vilken skickade data är taggade och levereras till intresserade konsumentapplikationer
- Ämnespartition: Eftersom ett enda ämne kan få mycket data på en gång, för att hålla Kafka horisontellt skalbart, är varje ämne uppdelat i partitioner och varje partition kan leva på vilken nodmaskin som helst i ett kluster. Låt oss försöka presentera det:
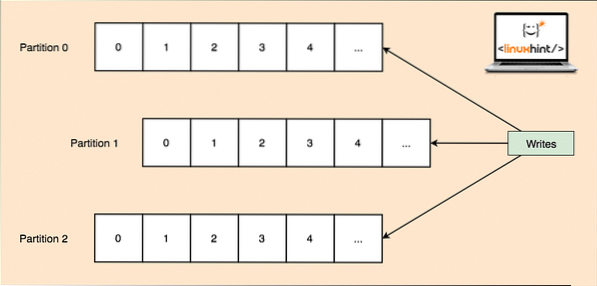
Ämnespartitioner
- Kopior: Som vi studerade ovan att ett ämne är indelat i partitioner, replikeras varje meddelandepost på flera noder i klustret för att upprätthålla ordningen och data för varje post om en av noderna dör.
- Konsumentgrupper: Flera konsumenter som är intresserade av samma ämne kan förvaras i en grupp som kallas en konsumentgrupp
- Offset: Kafka är skalbart eftersom det är konsumenterna som faktiskt lagrar vilket meddelande som hämtats av dem senast som ett "offset" -värde. Detta betyder att för samma ämne kan konsument A: s förskjutning ha ett värde på 5 vilket innebär att det måste bearbeta det sjätte paketet nästa och för konsumenten B kan förskjutningsvärdet vara 7 vilket betyder att det måste bearbeta åttonde paketet nästa. Detta tog bort beroendet av själva ämnet för att lagra denna metadata relaterad till varje konsument.
- Nod: En nod är en enda servermaskin i Apache Kafka-klustret.
- Klunga: Ett kluster är en grupp av noder i.e., en grupp servrar.
Konceptet för Ämne, Ämnespartitioner och förskjutning kan också klargöras med en illustrativ figur:
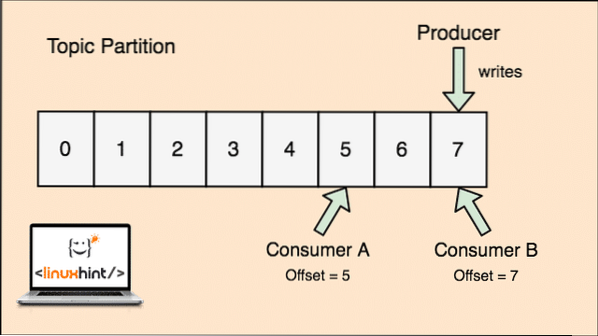
Ämnespartion och konsumentkompensation i Apache Kafka
Apache Kafka som meddelandesystem för Publish-subscribe
Med Kafka publicerar producentapplikationerna meddelanden som anländer till en Kafka-nod och inte direkt till en konsument. Från denna Kafka-nod konsumeras meddelanden av konsumentapplikationerna.
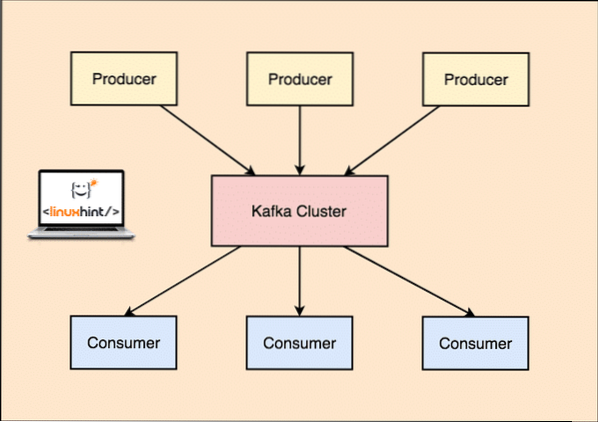
Kafka Producent och konsument
Eftersom ett enda ämne kan få mycket data på en gång, för att hålla Kafka horisontellt skalbar, är varje ämne uppdelat i partitioner och varje partition kan leva på vilken nodmaskin som helst i ett kluster.
Återigen registrerar Kafka Broker inte vilken konsument som har konsumerat hur många datapaket. Det är konsumenternas ansvar att hålla reda på de uppgifter de har konsumerat. På grund av att Kafka inte håller reda på bekräftelser och meddelanden i varje konsumentapplikation kan det hantera många fler konsumenter med försumbar inverkan på genomströmningen. I produktionen följer många applikationer till och med ett mönster av batchkonsumenter, vilket innebär att en konsument konsumerar alla meddelanden i en kö med jämna mellanrum.
Installation
För att börja använda Apache Kafka måste den installeras på maskinen. För att göra detta, läs Installera Apache Kafka på Ubuntu.
Användningsfall: Spårning av webbplatsanvändning
Kafka är ett utmärkt verktyg att använda när vi behöver spåra aktivitet på en webbplats. Spårningsdata inkluderar och är inte begränsat till sidvisningar, sökningar, uppladdningar eller andra åtgärder som användarna kan vidta. När en användare är på en webbplats kan användaren vidta valfritt antal åtgärder när han / hon surfar genom webbplatsen.
Till exempel, när en ny användare registrerar sig på en webbplats kan aktiviteten spåras i vilken ordning en ny användare utforskar funktionerna på en webbplats, om användaren ställer in sin profil efter behov eller föredrar att direkt hoppa till funktionerna i hemsida. När användaren klickar på en knapp samlas metadata för den knappen i ett datapaket och skickas till Kafka-klustret varifrån analystjänsten för applikationen kan samla in dessa data och ge användbar insikt om relaterad data. Om vi vill dela upp uppgifterna i steg, här är hur processen kommer att se ut:
- En användare registrerar sig på en webbplats och går in i instrumentpanelen. Användaren försöker komma åt en funktion direkt genom att interagera med en knapp.
- Webbapplikationen konstruerar ett meddelande med denna metadata till en ämnespartition av ämnet "klicka".
- Meddelandet läggs till i engagemangsloggen och förskjutningen ökas
- Konsumenten kan nu ta meddelandet från Kafka Broker och visa webbplatsanvändning i realtid och visa tidigare data om den återställer offset till ett eventuellt tidigare värde
Användningsfall: Meddelandekö
Apache Kafka är ett utmärkt verktyg som kan fungera som en ersättning för meddelandemäklarverktyg som RabbitMQ. Asynkrona meddelanden hjälper till att koppla bort applikationerna och skapar ett mycket skalbart system.
Precis som begreppet mikrotjänster, istället för att bygga en stor applikation, kan vi dela upp applikationen i flera delar och varje del har ett mycket specifikt ansvar. På så sätt kan de olika delarna skrivas på helt oberoende programmeringsspråk! Kafka har inbyggt partitionerings-, replikerings- och feltoleranssystem som gör det bra som ett storskaligt meddelandemäklarsystem.
Nyligen ses Kafka också som en mycket bra lösning för loggsamling som kan hantera mäklare för loggsamlingsserver och tillhandahålla dessa filer till ett centralt system. Med Kafka är det möjligt att generera alla händelser som du vill att någon annan del av din applikation ska veta om.
Använda Kafka på LinkedIn
Det är intressant att notera att Apache Kafka tidigare sågs och användes som ett sätt genom vilket datarörledningar kunde göras konsekventa och genom vilka data togs in i Hadoop. Kafka fungerade utmärkt när flera datakällor och destinationer var närvarande och det var inte möjligt att tillhandahålla en separat pipeline-process för varje kombination av källa och destination. LinkedIn's Kafka-arkitekt Jay Kreps beskriver detta välbekanta problem väl i ett blogginlägg:
Mitt eget engagemang i detta började runt 2008 efter att vi skickat vår nyckel-värde butik. Mitt nästa projekt var att försöka få en fungerande Hadoop-installation igång och flytta några av våra rekommendationsprocesser dit. Med liten erfarenhet inom detta område, budgeterade vi naturligtvis några veckor för att få in och ut data, och resten av vår tid för att implementera fina förutsägelsealgoritmer. Så började en lång slog.
Apache Kafka och Flume
Om du går ut för att jämföra dessa två på grundval av deras funktioner, hittar du många vanliga funktioner. Här är några av dem:
- Det rekommenderas att använda Kafka när du har flera applikationer som konsumerar data istället för Flume, som är speciellt gjord för att integreras med Hadoop och endast kan användas för att ta in data i HDFS och HBase. Flume är optimerad för HDFS-operationer.
- Med Kafka är det en nackdel att behöva koda producenter och konsumentapplikationer medan det i Flume har många inbyggda källor och sänkor. Det betyder att om befintliga behov matchar Flume-funktioner rekommenderas att du använder Flume själv för att spara tid.
- Flume kan konsumera data under flygning med hjälp av avlyssnare. Det kan vara viktigt för datamaskering och filtrering medan Kafka behöver ett externt strömbehandlingssystem.
- Det är möjligt för Kafka att använda Flume som konsument när vi behöver ta in data till HDFS och HBase. Det betyder att Kafka och Flume integreras riktigt bra.
- Kakfa och Flume kan garantera noll dataförlust med rätt konfiguration som också är lätt att uppnå. Fortfarande, för att påpeka, replikerar inte Flume händelser vilket innebär att om en av Flume-noder misslyckas kommer vi att förlora händelseåtkomst tills disken återställs
Slutsats
I den här lektionen tittade vi på många begrepp om Apache Kafka. Läs mer Kafka-baserade inlägg här.


